Kaleidoscope Performance with MCJIT
In a previous post I described the process of porting the LLVM Kaleidoscope tutorial program to use MCJIT as its execution engine. After navigating through a serious of road blocks we ended up with an implementation that was working as expected.So it works, but the next question is, “Is it any good?”
A lot of people considering the transition from the older JIT execution engine to MCJIT have concerns about the possible performance implications, particularly related to the fact that MCJIT doesn’t support lazy compilation. The older JIT engine will generate code for functions in an LLVM module one function at a time, delaying compilation of each function until it is about to be executed. The MCJIT engine operates on entire modules, generating code for all functions in a module at once. In the previous post, we modified the Kaleidoscope interpreter to create multiple modules as needed, but we’re still compiling the entire current module when a function is executed.
So what does that look like in terms of performance?
The Kaleidoscope interpreter operates on input from stdin. When you’re sitting at your keyboard typing functions and expressions, it seems perfectly responsive. It would take a lot of typing to create a module large enough to have a noticeable compilation time. Of course, we can also drive our interpreter by redirecting a file through stdin. This will be useful for measuring performance. Unfortunately, there aren’t a lot of large Kaleidoscope programs available that we can use as a benchmark.
Instead I wrote a Python script that will generate random Kaleidoscope functions and expressions. By varying a few script parameters you can change the characteristics of the generated Kaleidoscope script to simulate various workload scenarios (number of functions, operations per function, number of function definitions between execution and percentage of calls within functions). My Python script also generates a bash script that uses the Linux ‘time’ utility to get some crude performance and memory usage measurements. These results should not in any way be confused with accurate benchmark data, but they ought to at least give us a rough idea of where we are.
I made some minor changes to add a divide operator and a new output function (printlf) and to eliminate unnecessary output to stderr so that we aren’t timing the ‘dump’ functions.
Here’s how my new MCJIT-based toy compares to a version built with the older JIT engine:
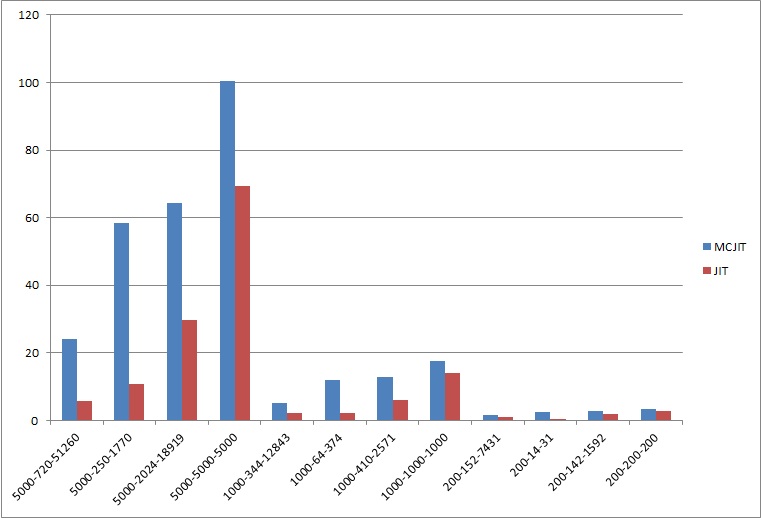
The numbers across the bottom here give some indication of the input being used. The first number is the number of functions in the script, the second number is the number of functions called at least once and the third number is the total number of calls that will be executed.
So it turns out that depending on the input the MCJIT version of the Kaleidoscope interpreter that we’ve created is anywhere between 1.25 and 5.5 times slower. That’s disappointing but not really unexpected. Remember that the JIT version never compiles functions that aren’t used, and that’s really the weakness that this comparison was intending to quantify. The more functions are called, the closer our MCJIT version is to the JIT version, which is what we’d expect.
We’ll talk about memory use later, but for now let’s just say that it follows a similar pattern.
The input sets I have are pretty trivial, so the actual code generated isn’t particularly interesting for performance analysis. I can tell you from experience that where both engines are able to use the same processor features they generate nearly identical code. (There’s a lot shared under the hood.) There are some new processor features that aren’t supported by the older JIT engine, but that’s not relevant for our current comparison.
Making MCJIT Lazy
Now that we have some idea of what we’re up against, let’s turn to the task of making a version of the MCJIT toy that attempts to mimic the lazy-compilation mode of the old JIT engine. In the version we’ve created to this point we’re delaying creation of our execution engine until something needs to be executed, but when we do compile we’re compiling everything in the Module, not just the functions that will be executed. That’s an inherent part of MCJIT’s design, so to get around it, we’re going to have to create a new module for each function and put off compiling each module until it is needed for linking. If you had a detailed knowledge of the code you’re compiling you could optimize function grouping, putting related functions together in a module and so forth, but for the current experiment we’ll take the most general approach possible.Once again, this is easier than you might expect.
Let’s start by moving the code that compiles a module into a new method in MCJITHelper().
ExecutionEngine *MCJITHelper::compileModule(Module *M) {Now the code in MCJITHelper::getPointerToFunction() that compiles the current module will look like this:
std::string ErrStr;
ExecutionEngine *NewEngine = EngineBuilder(M)
.setErrorStr(&ErrStr)
.setUseMCJIT(true)
.setMCJITMemoryManager(new HelpingMemoryManager(this))
.create();
if (!NewEngine) {
fprintf(stderr, "Could not create ExecutionEngine: %s\n", ErrStr.c_str());
exit(1);
}
// Create a function pass manager for this engine
FunctionPassManager *FPM = new FunctionPassManager(M);
// Set up the optimizer pipeline. Start with registering info about how the
// target lays out data structures.
FPM->add(new DataLayout(*NewEngine->getDataLayout()));
// Provide basic AliasAnalysis support for GVN.
FPM->add(createBasicAliasAnalysisPass());
// Promote allocas to registers.
FPM->add(createPromoteMemoryToRegisterPass());
// Do simple "peephole" optimizations and bit-twiddling optzns.
FPM->add(createInstructionCombiningPass());
// Reassociate expressions.
FPM->add(createReassociatePass());
// Eliminate Common SubExpressions.
FPM->add(createGVNPass());
// Simplify the control flow graph (deleting unreachable blocks, etc).
FPM->add(createCFGSimplificationPass());
FPM->doInitialization();
// For each function in the module
Module::iterator it;
Module::iterator end = M->end();
for (it = M->begin(); it != end; ++it) {
// Run the FPM on this function
FPM->run(*it);
}
// We don't need this anymore
delete FPM;
Engines.push_back(NewEngine);
NewEngine->finalizeObject();
return NewEngine;
}
// If we didn't find the function, see if we can generate it.It will also be helpful to have a function that ‘closes’ the current module.
if (OpenModule) {
ExecutionEngine * NewEngine = compileModule(OpenModule);
return NewEngine->getPointerToFunction(F);
}
void MCJITHelper::closeCurrentModule() {We don’t want to call this from MCJITHelper::getModuleForNewFunction as you might expect, because that is called for immediate expressions as well as function definitions. Instead, we’ll call it from the beginning of HandleDefinition(). This will cause the current module to be closed each time a function with a body is defined, but will still allow immediate expressions to be included in the last open module. We also need to call closeCurrentModule from compileModule if the module being compiled is the current module in order to handle the case of two consecutive immediate expressions.
OpenModule = NULL;
}
So far so good, but the problem we now face is that our current implementation of MCJITHelper::getPointerToFunction() and MCJITHelper::getPointerToNamedFunction() both assume that they will find all functions either in the current open module or an execution engine that has already been used to compile a module.
To fix that we’ll need to change our data structures. Instead of keeping a vector of modules and a vector of execution engines, we’ll use a map that correlates module pointers with execution engine pointers. If a module has no execution engine pointer in the map that will mean the module has not yet been compiled.
In our helper class definition, we replace this:
typedef std::vector<ExecutionEngine*> EngineVector;with this:
EngineVector Engines;
std::map<Module *, ExecutionEngine *> EngineMap;And with that we can re-write our getPointerToFunction methods to look like this:
void *MCJITHelper::getPointerToFunction(Function* F) {Both of these functions work in the same way. They iterate through our vector of Modules looking for a Module that contains a function with the name we are looking for. In the first case, we also check to see if this is exactly the function we’re looking for. (It might be a prototype.) Once we’ve found the right module, we check to see if the module has a corresponding execution engine. If it does, we ask that engine for a pointer to the function. If not, we compile the module and then ask the new execution engine for the pointer. This leaves modules in an uncompiled state until we need a function either for execution or to satisfy a linking request.
// Look for this function in an existing module
ModuleVector::iterator begin = Modules.begin();
ModuleVector::iterator end = Modules.end();
ModuleVector::iterator it;
std::string FnName = F->getName();
for (it = begin; it != end; ++it) {
Function *MF = (*it)->getFunction(FnName);
if (MF == F) {
std::map<Module*, ExecutionEngine*>::iterator eeIt = EngineMap.find(*it);
if (eeIt != EngineMap.end()) {
void *P = eeIt->second->getPointerToFunction(F);
if (P)
return P;
} else {
ExecutionEngine *EE = compileModule(*it);
void *P = EE->getPointerToFunction(F);
if (P)
return P;
}
}
}
return NULL;
}
void *MCJITHelper::getPointerToNamedFunction(const std::string &Name)
{
// Look for the functions in our modules, compiling only as necessary
ModuleVector::iterator begin = Modules.begin();
ModuleVector::iterator end = Modules.end();
ModuleVector::iterator it;
for (it = begin; it != end; ++it) {
Function *F = (*it)->getFunction(Name);
if (F && !F->empty()) {
std::map<Module*, ExecutionEngine*>::iterator eeIt = EngineMap.find(*it);
if (eeIt != EngineMap.end()) {
void *P = eeIt->second->getPointerToFunction(F);
if (P)
return P;
} else {
ExecutionEngine *EE = compileModule(*it);
void *P = EE->getPointerToFunction(F);
if (P)
return P;
}
}
}
return NULL;
}
You’ll notice that this code doesn’t populate the EngineMap. We’ll do that in the compileModule() function instead, where we were previously adding the new engine to the Engines vector. We’ll also need to change our clean up code in the MCJITHelper destructor.
MCJITHelper::~MCJITHelper()Note that once a module has been passed to an execution engine, the execution engine owns that module, so in each case we only need to delete a module or an execution engine, but never both.
{
// Walk the vector of modules.
ModuleVector::iterator it, end;
for (it = Modules.begin(), end = Modules.end();
it != end; ++it) {
// See if we have an execution engine for this module.
std::map<Module*, ExecutionEngine*>::iterator mapIt = EngineMap.find(*it);
// If we have an EE, the EE owns the module so just delete the EE.
if (mapIt != EngineMap.end()) {
delete mapIt->second;
} else {
// Otherwise, we still own the module. Delete it now.
delete *it;
}
}
}
Lazy Performance Analysis
At this point, the MCJIT-based version of our Kaleidoscope interpreter should be compiling lazily just like the old JIT-based implementation did. Let’s re-run our test workloads and see how it stacks up.Here are the new results.

That looks quite a bit better. The big spike in the fourth column is the case where each function is called immediately after it is defined. The MCJIT implementation is still about 1.3 times slower with 5000 functions in that case, but previously that was one of the better points of comparison for MCJIT. Now it’s the worst case scenario.
Also notice that with the new “lazy” MCJIT implementation there are a few cases where our MCJIT-based interpreter is quicker than the old JIT-based implementation.
Memory Consumption
Now let’s talk about memory usage. You can probably see without measurements that our new “lazy” implementation is going to consume more memory than the old implementation. We’re creating a new Module instance for each and every function that gets defined and a bunch more execution engine related objects every time one of these things gets compiled. But how bad is it?It’s bad. I’m not sure how far to trust the memory statistics I’m getting from the time utility, but assuming they at least reliable enough to be a rough guide the MCJIT implementation has some issues. In the cases where the MCJIT implementation has a performance advantage the memory consumption can be as little as 1.5 times the JIT implementation, but in the worst case scenario of each function being called immediately after it is defined the MCJIT implementation can take up to 10 times more memory than the JIT implementation.
What are we to make of this? Well, let’s start with a sanity check. As the introduction to the Kaleidoscope tutorial says the tutorial isn’t meant to be a good implementation -- “the code leaks memory, uses global variables all over the place, doesn’t use nice design patterns like visitors, etc... but it is very simple.”
There are some very basic things going on that waste a lot of memory, and those are amplified in our MCJIT implementation. For instance, when an immediate expression is used, we leave it in memory for the duration of program execution, even though we can be absolutely certain we’ll never reference it again.
Also, I don’t really have a feel for whether or not the sample inputs I’m using have any correspondence to a real world usage pattern. I haven’t done a detailed analysis of memory use, but at first glance it appears that a large chunk of the memory is being used to generate relocation tables for each generated object image. In theory we could drop those tables as soon as the object is fixed in memory (that is, after the call to finalizeObject), but we don’t. This problem is magnified by the fact that the workloads are heavily based on a network of random calls between functions, probably involving a disproportionately high number of cross module references. I’ve made no attempt to optimize that.
As I said, I just generated a bunch of random code and threw it at the interpreter. That’s true of the performance numbers too, of course. Remember, my goal here was just to try to get a ballpark feel for what the implementation looked like.
My ballpark feel is that with the “lazy” implementation the performance is going to be just about as good as the old JIT implementation, but it’s going to use more memory.
Next Steps
So what else can we do with this? Why would anyone want to go to the trouble of switching to MCJIT just to get something that performed just about as well but used more memory?I could say that you’ll get better ongoing support and adoption of new LLVM enhancements with MCJIT. While that’s true, it would probably leave you a bit frustrated.
Instead, what I’m going to tell you is that MCJIT has a great feature that will give it a huge leg up on the old JIT engine in many real world usage scenarios. But that’s going to have to wait until my next post….
The full source code listing for this post along with the scripts for generating test input are available in the trunk of the LLVM source tree at <llvm_root>/examples/Kaleidoscope/MCJIT.