FTL: WebKit’s LLVM based JIT
Over the past year, the WebKit project made tremendous progress on the ability to optimize JavaScript applications. A major part of that effort was the introduction of the Fourth Tier LLVM (FTL) JIT. The Fourth Tier JIT targets long-running JavaScript content and performs a level of optimization beyond WebKit's interpreter, baseline JIT, and high-level optimizing JIT. See the FTL Optimization Strategy section below for more on WebKit's tiered optimizations. The engineering advancements within WebKit that made the FTL possible were described by Filip Pizlo in the Surfin' Safari Blog post, Introducing the WebKit FTL JIT. On April 29, 2014, the WebKit team enabled FTL by default on trunk: r167958.This achievement also represents a significant milestone for the LLVM community. FTL makes it clear that LLVM can be used to accelerate a dynamically type checked languages in a competitive production environment. This in itself is a tremendous success story and shows the advantage of the highly modular and flexible design of LLVM. It is the first time that the LLVM infrastructure has supported self-modifying code, and the first time profile guided information has been used inside the LLVM JIT. Even though this project pioneered new territory for LLVM, it was in no way an academic exercise. To be successful, FTL must perform at least as well as non-FTL JavaScript engines in use today across a range of workloads without compromising reliability. This post describes the technical aspects of that accomplishment that relate to LLVM and future opportunities for LLVM to improve JIT compilation and the LLVM infrastructure overall.
- FTL Performance
- FTL Optimization Strategy
- LLVM Patch Points
- FTL-Style LLVM IR
- MCJIT and the LLVM C API
- Linking WebKit with LLVM
- FTL Efficiency
- Optimization Improvements
- Extending Patch Points
- Conclusion
FTL Performance
JavaScript pages are ubiquitous and users expect fast load times, which WebKit's architecture is well suited for. However, some JavaScript applications require nontrivial computation and may run for periods longer than one hundred milliseconds. These applications demand aggressive compiler optimization and code generation tuned for the target CPU. FTL brings the full gamut of compiler technology to bear on the problem.As with any high level language, high level optimizations must come first. Grafting an optimizing compiler backend onto an immature frontend would be futile. The marriage of WebKit's JIT with LLVM's optimizer and code generation works for two key reasons:
- Before translating to LLVM IR, WebKit's optimizing JIT operates on an IR that clearly expresses JavaScript semantics. Through type inference and profile-driven speculation, WebKit removes as much of the JavaScript abstraction penalty as possible.
- LLVM IR has now adopted features for supporting speculative, profile-driven optimization and avoiding the performance penalty associated with abstractions when they cannot be removed.
Asm.js is a subset if JavaScript that avoids abstraction penalties, allowing JITs to directly benefit from low-level performance optimization. Consequently, the performance advantage of FTL is likely to be quite apparent on asm.js benchmarks. But although FTL performs well on asm.js, it is in no way customized to the standard. In fact, with FTL, regular JavaScript code written in a style similar to asm.js will derive the same benefits. Furthermore, as WebKit's high-level optimizations become even more advanced, the benefits of FTL will expand to a broader set of idiomatic JavaScript code.
A convenient way to measure the impact of LLVM optimizations on JavaScript code is by running C/C++ benchmarks that have been compiled to asm.js code via emscripten. This allows us to compare native C/C++ performance with WebKit's third tier (DFG) compiler and with WebKit FTL.
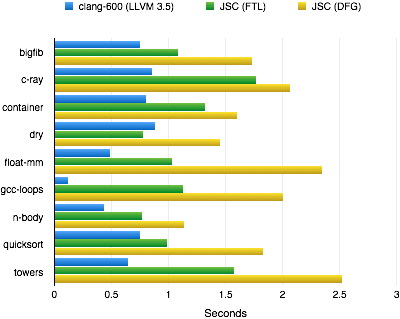
[1] gcc-loops is currently an outlier because clang performance recently sped up dramatically from auto-vectorization that has not been enabled yet in FTL.
FTL Optimization Strategy
WebKit's tiered architecture provides flexibility in balancing responsiveness, profile collection, and compiler optimization. The first tier is the low-level interpreter (LLInt). The second is the baseline JIT--a straightforward translation from JavaScript to machine code. WebKit's third tier is known as the Data Flow Graph (DFG) JIT. The DFG has its own high-level IR allowing it to perform aggressive JavaScript-specific optimization based on the profile data collected in earlier tiers. When running as a third tier, the DFG quickly emits code with additional profiling hooks. It may be invoked again as a fourth tier, but this time it produces LLVM IR for traditional compiler optimization.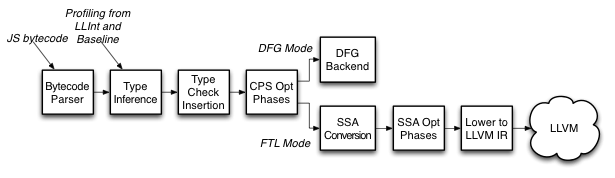
The DFG JIT front end generates LLVM IR in a form that is amenable to the same optimizations traditionally performed with C code. The most notable differences are summarized in FTL-Style LLVM IR.
LLVM Patch Points
Patch points are the key LLVM feature that allows dynamic type checking, inline caching, and runtime safety checks without penalizing performance. In October, 2013, we submitted a proposal to amend LLVM IR with patch points to the LLVM developer list. Since then, we've successfully implemented patch points for multiple architectures and their performance impact has been validated for various use cases, including branch-to-fail safety checks, inline caches, and code invalidation points. The details of the current design are explained in the LLVM specification of stack map and patch point intrinsics.Patch points are actually two features in one intrinsic. The first feature is the ability to identify the location of specific values at the intrinsic's final instruction address. During code emission, LLVM records that information as meta-data alongside the object code in what we call a "stack map". A stack map communicates to the runtime the location of important values. This is a slight misnomer given that locations may refer to register names. Typically, the runtime will read values out of stack map locations when it needs to reconstruct a stack frame. This commonly occurs during "deoptimization"--the process of replacing an FTL stack frame with a lower-tier frame.
The second feature of patch points is the ability of the runtime to patch the compiled code at specific instruction address. To allow this, the intrinsic reserves a fixed amount of instruction encoding space and records the instruction address of that space along with the stack map. Because the runtime needs to know the location of values precisely at the point it patches code, the two features must be combined into one intrinsic.
Patch points are viewed by LLVM passes much like unknown call sites. An important aspect of their design is the ability to specify the effective calling convention. For example, code invalidation points are almost never taken and the call site should not clobber any registers, otherwise the register allocator could be severely restricted by frequent runtime checks. An optional feature of stack maps is the ability to record the registers that are actually live in compiled code at each call site. This way the JIT can declare a call as preserving all registers to maximize compiler freedom, but at the same time the runtime can avoid unnecessary save and restore operations when the "cold" call is actually taken.
To better support inline cache optimizations, LLVM now has a special "anyregcc" calling convention. This convention allows any number of arguments to be forced into registers without pinning down the name of the register. Consequently, the compiler does not have to place arguments in particular registers or stack locations, or emit extra copies and spills around call sites, and the runtime can emit efficient patched code sequences that operate directly on registers.
The current patch point design is labeled experimental so that it may continue to evolve without preserving bitcode compatibility. LLVM should soon be ready to adopt the patch point intrinsic in its final form. However, the current design should first be extended to capture the semantics of high level language runtime checks. See Extending Patchpoints.
FTL-Style LLVM IR
FTL attempts to generate LLVM IR that closely resembles what the optimizer expects to see from other typical compiler frontends. Nonetheless, lowering JavaScript semantics into LLVM operations tends to result in IR with different characteristics from statically compiled C code. This section summarizes those differences. More details and examples will be provided in a subsequent blog post.The prevalence of patch points in the IR means that values tend to have many more uses and can be live into a large number of patch point call sites. FTL emits patch points for a few distinct situations. First, when the FTL front end (DFG) fails to eliminate type checks or bounds checks, it emits explicit compare and branch operations in the IR. The branch target lands at a patch point intrinsic followed by unreachable. This can result in much more branchy code than LLVM typically handles with C benchmarks. Fortunately, LLVM's awareness of branch probability means that the branch-to-fail idiom does not excessively hinder optimization and code generation. Heap access and polymorphic calls also use patch points, but these are emitted directly inline with the hot path. This allows the runtime to implement inline caches with specific instruction sequences that can be patched as program behavior evolves. Finally, runtime calls may act as code invalidation points. A runtime event, such as a potential change in object layout, may invalidate speculatively optimized code. In this case WebKit emits nop patch points that can be overwritten with a separate runtime call at an invalidation event. This effectively invalidates all code that follows the original runtime call.
Some type checks result in multiple fast paths. For example, WebKit may check a numeric value for either a floating-point or fixed point representation and emit LLVM IR for both paths. This may result in a sequence of redundant checks interleaved with control flow merges.
To support integer overflow checks, when they cannot be removed through optimization, FTL emits llvm.sadd.with.overflow intrinsics in place of normal add instructions. These intrinsics ensure that the code generator produces an optimal code sequence for the overflow checks. They are also used by other active LLVM projects and are gradually gaining support within LLVM optimization passes.
LLVM heuristics are often sufficient to guess branch probability. However FTL makes the job easier by directly emitting LLVM branch weight meta-data based on profiling. This is particularly important when partially compiling a method starting at the inner loop. Such compilations can squash nested loops so that LLVM's heuristics can no longer infer the loop depth from the CFG structure.
FTL builds an internal model of the JavaScript program's type system determined by profiling. It conveys this information to LLVM via type-based-alias-analysis (tbaa) meta-data. In FTL tbaa, each object field has a unique tag. This is a very effective approach to memory disambiguation, and much simpler than the access-path scheme that clang now uses.
Another way that FTL deviates from the norm, is in its use of inttoptr instructions. These are used to materialize addresses of runtime objects, including all data and code from outside the current compilation unit (currently a single method at a time). inttoptr is also used to convert an untyped JS value to a pointer. Occasionally, pointer arithmetic is performed on non-pointer types rather than using getelementptr instructions. This is primarily a convenience and has not proven to hinder optimization. FTL's use of tbaa is effective enough to obviate the need to analyze getelementptr when the base address is already an unknown object.
An important pattern that occurs in FTL's LLVM IR is the repeated use of the same large constants that are used as masks to disambiguate tagged values, or several constants that represent global addresses that tend to be at small offsets from each other. LLVM's current one basic block a time code generation approach resulted in redundant rematerialization of the same large constant in each basic block. The fact that FTL creates a large number of basic blocks even further exacerbated this problem. The LLVM code generator has been enhanced to avoid these expensive repeated rematerialization of such constant values.
MCJIT and the LLVM C API
The FTL JIT successfully leverages LLVM's existing MCJIT framework for runtime compilation. MCJIT was designed as a low-level toolkit that allows runtime compilers to be built by reusing as much of the static compiler's machinery as possible. This approach improves maintainability on the LLVM side. It integrates with the existing compiler toolchain and allows developers to test features of the runtime compiler without understanding a particular JIT client. The current API, however, does not provide a simple out-of-the-box abstraction for portable JITs. Overcoming the impedance mismatch between WebKit goals and the low-level MCJIT API required close collaboration between WebKit and LLVM engineers. As LLVM becomes more important as a JIT platform, it should provide a more complete C API to improve interoperability with JIT clients and decrease the fragility and maintenance burden within the client code base.Bridging the gap between LLVM internals and portable JITs can be accomplished by providing more convenience wrappers around the existing MCJIT framework and adding richer C APIs for object code parsing and introspection. Ideally, a cross-platform JIT client like WebKit should not need to embed target-specific details about LLVM code generation on the client side. The JIT should be able to request LLVM to emit code for the current host process without understanding LLVM's language of target triples and CPU features. LLVM could generally provide a more obvious C API for lazily invoking runtime compilation. Along these lines, a JIT should be able to reuse the MCJIT execution engine for multiple modules without the overhead of reinitializing pass manager instances each time. An API also needs to be added for configuring the code generation pass manager. Most of the coordination between the JIT and LLVM now occurs directly through a memory manager API, which can be awkward for the JIT client. For example, WebKit looks for platform-specific section names when allocating section memory in order to locate frame meta-data and debug information. A better interface for WebKit would be a portable API that communicates object code meta-data, including frame information and stack maps. In general, the JIT codebase should not need to provide its own support for platform-specific object file formats. LLVM already has this support, it only needs to be exposed through the C API. Similarly, a JIT should be able to lookup line numbers without implementing its own DWARF parser. An additional layer of functionality for general purpose debug info parsing and object code introspection would not be specific to JIT compilation and could benefit a variety of LLVM clients.
Linking WebKit with LLVM
FTL illustrates an important use case for LLVM: embedding LLVM optimization and codegen libraries cleanly within a larger application running in the same process. The ideal solution is to build a set of LLVM components as a shared library that exports only a limited C API. Several problems have made this a challenging endeavor:- The dynamic link time initialization overhead of the static initializers that LLVM defines is unacceptable at program launch time - especially if only parts of the library or nothing at all are used.
- LLVM initializes global variables that require running exit-time destructors. This causes a multi-threaded parent application that attempts to exit normally to crash instead.
- As with static initializers, weak vtables introduce an unnecessary and unacceptable dynamic link time overhead.
- In general only a limited set of methods - the LLVM API - should be exported from the shared library.
- LLVM usurps process-level API calls like assert, raise, and abort.
- The resulting size of the LLVM shared library naively built from static libraries is larger than it needs to be. Build logic and conditional compilation should be added to ensure that only the passes and platform support required by the JIT client are ultimately linked into the shared library.
FTL Efficiency
The LLVM optimizer and code generator are composed of generic, retargetable components designed to generate optimal code across an extremely diverse range of platforms. The compile time cost of this infrastructure is substantial and may be an order of magnitude greater than that of a custom-built JIT. Fortunately, WebKit's architecture for concurrent, tiered compilation largely sidesteps this penalty. Nonetheless, there is considerable opportunity to reengineer LLVM for use as a JIT, which will decrease FTL's CPU consumption and increase the breadth of JavaScript applications that benefit from FTL.When running in a JIT environment, an opportunity exists for LLVM to strike a better balance between compile time and optimization strength. To this end, an alternate "compile-fast" optimization pass pipeline should be standardized so that the LLVM community can work together to maintain an ideal sequence of lighter-weight passes. Long running, iterative IR optimization passes, such as GVN, should be adapted to optionally run in fewer iterations. Hodge-podge passes like InstCombine that run many times should be optionally broken up so that some subset of functionality can run at different times: for example, canonicalize first and optimize later.
There are also considerable opportunities for improving code generation efficiency which will benefit JITs and static compilers alike. LLVM machine IR should be generated directly from LLVM IR without generating a Selection DAG, as proposed by Jakob Olesen in his Proposal for a global instruction selector. The benefit of this improvement would be considerable and widespread. More specific to high level languages, codegen passes should be tuned to handle branchy code more efficiently. For example, the register allocator can be taught to skip expensive analysis at points in the code where branches are not expected to be executed.
One overhead that will remain with the above improvements is simply the cost of bridging WebKit's DFG IR into LLVM IR. This involves lowering to SSA form and constructing LLVM instructions, which currently takes significant amount of time relative to DFG's non-LLVM codegen path. With some scrutiny, this could likely be made more efficient.
Optimization Improvements
Without incurring significant compile time increase, LLVM optimizations can be further improved to handle prevalent idioms in JavaScript programs. One straightforward LLVM IR enhancement would be to associate type-based alias information with call sites. This would improve redundant instruction elimination across runtime calls and patch points. Another area of improvement would be better handling of branch-and-merge idioms. These are quite common in FTL produced IR and can improved through CFG simplification, jump threading, or tail duplication. With careful pass pipeline management, loop optimizations can be enabled, such as auto-vectorization. Once LLVM is analyzing loops, bounds and overflow check elimination optimization can also be implemented. To do this well, patch points will need to be extended with new semantics.Extending Patch Points
In settings like JavaScript and other high level languages, patch points will be used to transfer control to the runtime when speculative optimization fails in the sense that the program behaves differently than predicted. It is always safe to assume a misprediction and give control back to the runtime because the runtime always knows how to recover. Consequently, patch points could optionally be associated with a check condition and given the following semantics: the patch point code sequence must be executed whenever the condition holds, but may safely be executed at its current location under any superset of the condition. When combined with LLVM loop optimization, the conditional patch point semantics would allow powerful optimization of runtime checks. In particular, bounds and overflow checks could be safely hoisted outside loops. For example, the following simplified IR:
%a = cmp <TrapConditionA>
call @patchpoint(1, %a, <state-before-loop>)
Loop:
%b = cmp <TrapConditionB>
@patchpoint(2, %b, <state-inside-loop>)
<do something...>
Could be safely optimized into:
%c = cmp <TrapConditionC> // where C implies both A and B
@patchpoint(1, %c, <state-before-loop>)
Loop:
do something...
Generally, high level optimization requiring knowledge of language-specific semantics is best performed on a higher level IR. But in this case, extending LLVM with one aspect of high level semantics allows LLVM's loop and expression analysis to be directly leveraged and naturally extended into a new class of optimization.