ThinLTO: Scalable and Incremental LTO
ThinLTO was first introduced at EuroLLVM in 2015, with results shown from a prototype implementation within clang and LLVM. Since then, the design was reviewed through several RFCs, it has been implemented in LLVM (for gold and libLTO), and tuning is ongoing. Results already show good performance for a number of benchmarks, with compile time close to a non-LTO build.
This blog post covers the background, design, current status and usage information.
LTO Background and Motivation
LTO (Link Time Optimization) is a method for achieving better runtime performance through whole-program analysis and cross-module optimization. During the compile phase, clang will emit LLVM bitcode instead of an object file. The linker recognizes these bitcode files and invokes LLVM during the link to generate the final objects that will constitute the executable. The LLVM implementation loads all input bitcode files and merges them together to produce a single Module. The interprocedural analyses (IPA) as well as the interprocedural optimizations (IPO) are performed serially on this monolithic Module.

What this means in practice is that LTO often requires a large amount of memory (to hold all IR at once) and is very slow. And with debug information enabled via -g, the size of the IR and the resulting memory requirements are significantly larger. Even without debug information, this is prohibitive for very large applications, or when compiling on memory-constrained machines. It also makes incremental builds less effective, as everything from the LTO step on must be re-executed when any input source changes.
ThinLTO Design
ThinLTO is a new approach that is designed to scale like a non-LTO build, while retaining most of the performance achievement of full LTO.
In ThinLTO, the serial step is very thin and fast. This is because instead of loading the bitcode and merging a single monolithic module to perform these analyses, it utilizes compact summaries of each module for global analyses in the serial link step, as well as an index of function locations for later cross module importing. The function importing and other IPO transformations are performed later when the modules are optimized in fully parallel backends.
The key transformation enabled by ThinLTO global analyses is function importing, in which only those functions likely to be inlined are imported into each module. This minimizes the memory overhead in each ThinLTO backend, while maximizing the most impactful cross module optimization opportunities. The IPO transformations are therefore performed on each module extended with its imported functions.
The ThinLTO process is divided into 3 phases:
- Compile: Generate IR as with full LTO mode, but extended with module summaries
- Thin Link: Thin linker plugin layer to combine summaries and perform global analyses
- ThinLTO backend: Parallel backends with summary-based importing and optimizations

By default, linkers that support ThinLTO (see below) are set up to launch the ThinLTO backends in threads. So the distinction between the second and third phases is transparent to the user.
The key enabler for this process are the summaries emitted during phase 1. These summaries are emitted using the bitcode format, but designed so that they can be separately loaded without involving an LLVMContext or any other expensive construction. Each global variable and function has an entry in the module summary. An entry contains metadata that abstracts the symbol it is describing. For example, a function is abstracted with its linkage type, the number of instructions it contains, and optional profiling information (PGO). Additionally, every reference (address taken, direct call) to another global is recorded. This information enables building a complete reference graph during the Thin Link phase, and subsequent fast analyses using the global summary information.
Current Status
ThinLTO is currently supported in both the gold plugin as well as in ld64 starting with Xcode 8. Additionally, support is currently being added to the lld linker. The 3.9 release of clang will have ThinLTO accessible using the -flto=thin command line option.
While tuning is still in progress, ThinLTO already performs well compared to LTO, in many cases matching the performance improvement. In a few cases ThinLTO even outperforms full LTO, most likely because the higher scalability of ThinLTO allows using a more aggressive backend optimization pipeline (similar to that of a non-LTO build).
The following results were collected for the C/C++ SPEC cpu2006 benchmarks on an 8-core 2.6GHz Intel Xeon E5-2689. Each benchmark was run in isolation three times and results are shown for the average of the three runs.
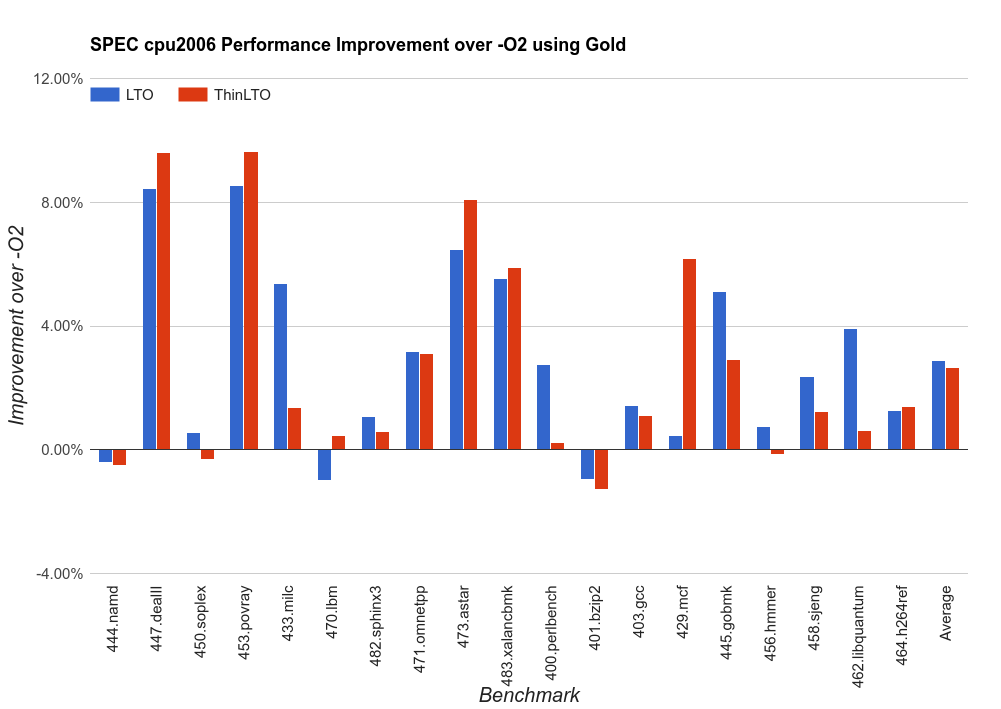
Critically, due to the scalable design of ThinLTO, this performance is achieved with a build time that stays within a non-LTO build scale. The following build times were collected on a 20 core 2.8GHz Intel Xeon CPU E5-2680 v2, running Linux and using the gold linker. The results are for an end-to-end build of clang (ninja clang) from a clean build directory, so it includes all the compile steps and links of intermediate binaries such as llvm-tblgen and clang-tblgen.

Release build shows how ThinLTO build time is very comparable to a non-LTO build. Adding -gline-tables-only adds a very small overhead, and ThinLTO is again similar to the regular non-LTO build. However with full debug information, ThinLTO is still somewhat slower than a non-LTO build due to the additional overhead during importing. Ongoing improvements to debug metadata representation and handling are expected to continue to reduce this overhead. In all cases, full LTO is actually significantly slower.
On the memory consumption side, the improvements are significant. Over the last two years, FullLTO was significantly improved, as shown on the chart below, but our measurement shows that ThinLTO keeps a large advantage.

Usage Information
To utilize ThinLTO, simply add the -flto=thin option to compile and link. E.g.
% clang -flto=thin -O2 file1.c file2.c -c% clang -flto=thin -O2 file1.o file2.o -o a.out
As mentioned earlier, by default the linkers will launch the ThinLTO backend threads in parallel, passing the resulting native object files back to the linker for the final native link. As such, the usage model the same as non- LTO. Similar to regular LTO, for Linux this requires using the gold linker configured with plugins enabled or ld64 starting with Xcode 8.
Distributed Build Support
To take advantage of a distributed build system, the parallel ThinLTO backends can each be launched as a separate process. To support this, the gold plugin provides a thinlto_index_only option that causes the link to exit after creating the combined index and performing global analysis.
Additionally, in this mode:
- Instead of using a monolithic combined index, a separate individual index file is written per backend containing the necessary portions of the combined index for recording the imports and any other global summary based optimization decisions that should be acted on in the backend.
- A plain text listing of the bitcode files each module will import from is optionally emitted to aid in distributed build file staging (thinlto-emit-imports-files plugin option).
The backends can be launched by invoking clang on the bitcode and providing its index via an option. Finally, the resulting native objects are linked to generate the final binary. For example:
% clang -flto=thin -O2 file1.c file2.c -c
% clang -flto=thin -O2 file1.o file2.o -Wl,-plugin-opt,-thinlto-index-only
% clang -O2 -o file1.native.o -x ir file1.o -c -fthinlto-index=./file1.o.thinlto.bc
% clang -O2 -o file2.native.o -x ir file2.o -c -fthinlto-index=./file2.o.thinlto.bc
% clang file1.native.o file2.native.o -o a.out
Incremental ThinLTO Support
With full LTO, only the initial compile steps can be performed incrementally. If any input has changed, the expensive serial IPA/IPO step must be redone.
With ThinLTO, the serial Thin Link step must be redone if any input has changed, however, as noted earlier this is small and fast, and does not involve loading any module. And any particular ThinLTO backend must be redone iff:
- The corresponding (primary) module’s bitcode changed
- The list of imports into or exports from the module changed
- The bitcode for any module being imported from has changed
- Any global analysis result affecting either the primary module or anything it imports has changed.
For single machine builds, where the threads are launched by the linker, incremental builds can be achieved by caching the module after applying the global summary based optimizations such as importing, using a hash of the information listed above as the key. This caching is already supported in libLTO’s ThinLTO handling, which is used by ld64. To enable it, the link step needs to be passed an extra flag: -Wl,-cache_path_lto,/path/to/cache
For distributed builds, the above information in items 2-4 are all serialized into the individual index files. So the build system can compare the contents of the input bitcode files (the primary module’s bitcode and any it imports from) along with the combined index against those from an earlier build to decide if a particular ThinLTO backend must be redone. To make this process more efficient, the content of the bitcode file is hashed when emitted during the compile phase, and the result is stored in the bitcode file itself so that the cache can be queried during the Thin Link step without reading the IR.
The chart below illustrates the full build time of clang in three different situations:
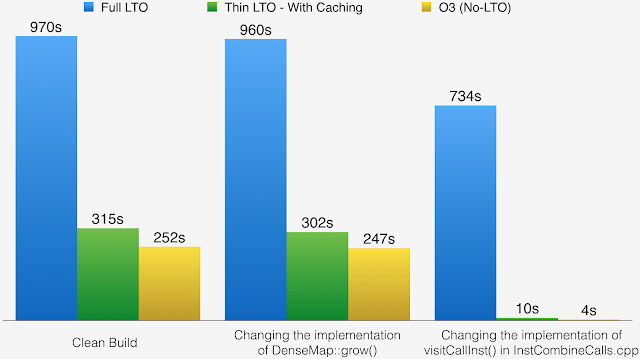
The chart below illustrates the full build time of clang in three different situations:
- The full link following a clean build.
- The developer fixes the implementation of DenseMap::grow(). This is a widely used header in the project, which forces to rebuild a large number of files.
- The developer fixes the implementation of visitCallInst() in InstCombineCalls.cpp. This an implementation file and incremental build should be fast.

These results illustrate how full LTO is not friendly with incremental build, and show how ThinLTO is providing an incremental link-time very close to a non-LTO build.