The Glasgow Haskell Compiler and LLVM
If you read the LLVM 2.7 release notes carefully you would have noticed that one of the new external users is the Glasgow Haskell Compiler (GHC). As the author of the LLVM backend for GHC, I have been invited to write a post detailing the design of the backend and my experiences with using LLVM. This is that post :).I began work on the backend around July last year, undertaking it as part of an honours thesis for my bachelor of Computer Science. Currently the backend is quite stable and capable on Linux x86, able to bootstrap GHC itself. Other platforms haven't received any attention yet.
What is GHC and Haskell
GHC is a compiler for Haskell, a standardized, lazy, functional programming language. Haskell supports features such as static typing with type inference, lazy evaluation, pattern matching, list comprehension, type classes and type polymorphism. GHC is the most popular Haskell compiler, it compiles Haskell to native code and is supported of X86, PowerPC and SPARC.Existing pipeline
Before the LLVM backend was added, GHC already supported two backends, a C code generator and a native code generator (NCG).The C code generator was the first backend implemented and it works pretty well but is slow and fragile due to its use of many GCC specific extensions and need to post processes the assembly code produced by GCC to implement optimisations which aren't possible to do in the C code. The native code generator was started later to avoid these problems. It is around 2-3x quicker than the C backend and generally reduces the runtime of a Haskell program by around 5%. GHC developers are hoping to depreciate the C backend in the next major release.
Why an LLVM backend?
- Offload work: Building a high performance compiler backend is a huge amount of work, LLVM for example was started around 10 years ago. Going forward, the LLVM backend should be a lot less work to maintain and extend than either the C backend or NCG. It will also benefit from any future improvements to LLVM.
- Optimisation passes: GHC does a great job of producing fast Haskell programs. However, there are a large number of lower level optimisations (particularly the kind that require machine specific knowledge) that it doesn't currently implement. Using LLVM should give us most of them for free.
- The LLVM Framework: Perhaps the most appealing feature of LLVM is that it has been designed from the start to be a compiler framework. For researchers like the GHC developers, this is a great benefit and makes LLVM a very fun playground. For example, within a couple of days of the public release of the LLVM backend one developer, Don Stewart, wrote a genetic algorithm to find the best LLVM optimisation pipeline to use for various Haskell programs (you can find his blog post about this here).
Show me the speed
That's enough reasoning for now though, lets instead jump right in and see GHC's LLVM backend in action. I'll also use this opportunity to do a little Haskell promoting as well, so you've been warned :).For a nice simple problem to solve lets find the starting number under 1 million that generates the longest hailstone sequence. The hailstone sequence is a number sequence generated from a starting number n by the following rules:
- if n is even, the next number is n/2
- if n is odd, the next number is 3n + 1
- if n is 1, stop.
#include <stdio.h>
int main(int argc, char **argv) {
int longest = 0, terms = 0, this_terms = 1, i;
unsigned long j;
for (i = 1; i < 1000000; i++) {
j = i;
this_terms = 1;
while (j != 1) {
this_terms++;
j = j % 2 == 0 ? j / 2 : 3 * j + 1;
}
if (this_terms > terms) {
terms = this_terms;
longest = i;
}
}
printf("longest: %d (%d)\n", longest, terms);
return 0;
}
--------
import Data.Word
collatzLen :: Int -> Word32 -> Int
collatzLen c 1 = c
collatzLen c n | n `mod` 2 == 0 = collatzLen (c+1) $ n `div` 2
| otherwise = collatzLen (c+1) $ 3*n+1
pmax x n = x `max` (collatzLen 1 n, n)
main = print . solve $ 1000000
where solve xs = foldl pmax (1,1) [2..xs-1]
Compiling the Haskell solution with the various backend gives the following runtime:
- GHC-6.13 (NCG): 2.876s
- GHC-6.13 (C): 0.576s
- GHC-6.13 (LLVM): 0.516s
- Clang-1.1: 0.526s
- GCC-4.4.3: 0.335s
One of the reasons I went with this example program is that I wanted to show off Haskell a little by demonstrating how easy it is to parallelize the solution:
import Control.Parallel
import Data.Word
collatzLen :: Int -> Word32 -> Int
collatzLen c 1 = c
collatzLen c n | n `mod` 2 == 0 = collatzLen (c+1) $ n `div` 2
| otherwise = collatzLen (c+1) $ 3*n+1
pmax x n = x `max` (collatzLen 1 n, n)
main = print soln
where
solve xs = foldl pmax (1,1) xs
s1 = solve [2..500000]
s2 = solve [500001..999999]
soln = s2 `par` (s1 `pseq` max s1 s2)
That's all! We simply divide the problem into two parts and combine them using Haskell's 'par' and 'pseq' constructs that tell the compiler to run the two parts 's1' and 's2' in parallel. And the run time (using LLVM of course):
- GHC-6.13 (Parallel, LLVM): 0.312
Finally, lets look at a bigger and more 'realistic' program and see how the LLVM backend performs. For this we will use HRay, a ray tracer implemented in Haskell. Using it to generate the image below we get the following run times:

- GHC (NCG): 29.499
- GHC (C): 29.043
- GHC (LLVM): 20.774
Backend overview
Lets look quickly at the job that the LLVM backend has to perform. GHC uses two major intermediate representations for compiling Haskell, the first being Core. Core is a functional language, basically a form of typed lambda calculus and its in this form that GHC does most of its optimisation work. There is also a IR called STG, its very similar to Core but is slightly easier to work with for procedural code generation.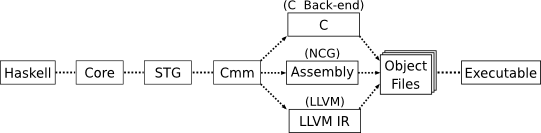
The second major IR is C minus minus (Cmm), which is low level imperative language designed to act as an interface between the high level Haskell compiler parts and the low level code generation. Cmm as a language is quite similar to LLVM in terms of design and feature set (e.g both use bit types such as i32...). The syntax is quite different though with Cmm looking a little like C and LLVM looking like assembly. The similarity of the two shouldn't really come as much of a surprise since they are both positioned at the same point in a compiler pipeline and also because Cmm is mostly a subset of the C-- language. C-- is a language designed by one of the primary GHC developers (Simon Peyton Jones) and others to act as a universal IR for compiler writers to target, very much like LLVM. (The research focus of C-- was quite different from LLVM though, C-- was designed to try to solve the problem of supporting high level language features like garbage collection and exceptions in a universal language with zero overhead. LLVM seems to be focused on supporting aggressive optimisation of a universal language). The C-- project never managed to take off like LLVM did though and so now Cmm simply serves as a good IR for GHC backends to work with.
The LLVM backend fits into the GHC pipeline after Cmm, so its job is to compile from Cmm to LLVM Assembly. This is mostly straight forward because of the similarity of the two languages.
The new calling convention
There was one major challenge though in writing the backend where LLVM didn't provide the features needed to properly implement Haskell and so I needed to extend LLVM. This extension is the new calling convention I wrote of at the start of the post and to explain why its necessary we'll have to look very briefly at the execution model for Haskell used by GHC.GHC defines an abstract machine that implements the execution model for Haskell code. This is called the 'STG Machine' (or Spineless Tagless G-Machine) and its job is to evaluate the final, functional IR used by GHC, STG. The STG machine consists of three main parts, registers, a stack and a heap. For this stack, GHC doesn't use the standard C stack but implements its own. What we are concerned with though is just how the registers are implemented. The easiest method is to just store them all in memory as a structure and indeed GHC supports this method (its refereed to as 'unregistered mode' and is used for easier porting of GHC). However because of how often they are accessed a far more efficient way to implement them is to map them onto real hardware registers, which roughly halves the runtime of a typical Haskell program. So this is what GHC does, although as there are far too many STG machine registers to map onto real registers, it has to still store some of them in memory.
This is a problem for the LLVM backend though as it has no control over the register allocation. We can still create a working backend by only supporting 'unregistered mode' but this isn't very useful due to the poor performance. Also we aren't just focused on performance, compatibility with the other backends is a major concern. We need to support the same register mapping as they use so that Haskell code compiled by LLVM will be able to link with code compiled by the other backends. Lets look quickly at how the other backends achieve this register mapping.
With the native code generator its very straight forward since it has full control over the register allocation. How about the C backend though? Typically this would be a problem for C as well since it offers no control over register allocation. Thankfully GCC offers an extension, 'Global Register Variables', which allows you to assign a global variable to always reside in a specific hardware register. GCC implements this feature basically by removing the register specified from the list of known registers that its register allocator uses.
So the solution for LLVM is a new calling convention but how does this work? Well the calling convention passes arguments in the hardware registers that GHC expects to find the STG machine registers in. So on entry to any function they're in the correct place. Unlike with the NCG or C backend this doesn't exclusively reserve the registers, so in the middle of a function we can't guarantee that the STG machine registers will still be in the hardware registers, they may have been spilled to the stack. This is fine, in fact its an improvement. It allows LLVM to generate the most efficient register allocation, having more registers and flexibility than the other backends, while still maintaining compatibility with them since on any function entry the STG machine registers are guaranteed to be in the correct hardware registers.
Evaluation of the backend
The two benchmarks at the start gave you a taste of the performance improvements that LLVM is able to bring to GHC. However, how does it perform across the board? The best way I have to test this at the moment is by using a benchmark suite included with GHC called 'nofib'. Currently this suite puts the native code generators in first place, with the LLVM code generator a close second at 3% behind in run time and the C code generator in last place at 6% behind. An important characteristic of the LLVM code generator though is that its consistent. At its best its able to beat the existing backends with a 2x speed-up in run time while at its worst its usually within 3 - 30% of the performance of the best of the NCG or C backend. So you don't get any cases like the NCG has where it really looses out. Its also worth noting that no work has been done yet on optimising the performance of the LLVM backend.The other great benefit of the LLVM code generator is its smaller size and simpler code base. The NCG clocks in at ~20,500 lines of code, the C backend at ~5,300 and the LLVM backend at ~3,100. For the C backend, around 2,000 lines of that code are Perl code which does the post processing of the GCC produced assembly, fragile and complex code full of regular expressions. For the LLVM backend around 1,200 lines of its code are a library for generating and printing out LLVM Assembly, so the complex code generation code is only at around 1,800 lines.
Problems with backend
There is one major issue remaining with the LLVM backend that I currently know of, its inability to implement a optimisation used by GHC called 'TABLES_NEXT_TO_CODE' (TNTC).For functions, GHC needs to associate some meta-data with them, referred to as an info table. This table contains information about the function used by the run time system. Without the TNTC optimisation the linking of a table and function is done by having the info table contain a pointer to the function. With the TNTC optimisation the code and data is laid out so that the info table resides immediately before the function. This allows both the function and its info table to be accessed from the same pointer, which speeds up access of a function (one pointer lookup instead of two) and reduces the size of info tables.

How the other two backends handle this is the similar to the STG machine registers. The NCG can implement this with no problems, while the C backend is unable to do this in plain C. However, this time with no GCC extensions able to implement the optimisation either it resorts to post processing the assembly code produced by GCC. For LLVM we have the same problem as the C backend, LLVM doesn't provide a way to explicitly layout the code and data in the object file like we need. This optimisation is fairly significant, giving about a 5% reduction in run times when enabled, so its something I hope to fix up in the future either by adding support for it to LLVM or by post processing the assembly as the C backend does.
Success of LLVM?
When I asked for the GHC calling convention to be included in LLVM a price was asked of me, a blog post, this one. So I asked Chris what he felt I should write about. There is just one point left to cover to make sure I've paid in full.> [Chris Lattner]: Talking about what you think is good and what you think should be improved in LLVM would also be great. :)
I'd like to see LLVM gain the needed features to be able to implement the TNTC optimisation in the GHC backend. It would also be great if LLVM was better supported on Sparc as that's a platform GHC works reasonably well on where LLVM doesn't. As for what is good? When you look at the GHC LLVM backend, it achieves very close or better performance than existing backends that have been around for years, while having a smaller and simpler code base. I think you also gain a lot from the LLVM type system, it really helped catch most of the bugs fixed so far in the backend. Finally the great documentation. This is something I really appreciate and often is lacking in many projects.
Future
Since finishing my thesis at the end of 2009, I haven't been able to get much work done on the LLVM backend. However I was lucky enough to receive an internship with Microsoft Research in Cambridge, UK, where two of the primary GHC developers (Simon Marlow & Simon Peyton Jones) work. As part of this I'll be looking to implement the TNTC optimisation as well as general stabilisation and optimisation work. The backend only takes advantage of features offered in 2.5, so I also need to investigate and update it to use the newer 2.6 and 2.7 features. There is also a Google Summer of Code student, Alp Mestanogullari, who is working on the backend. He is looking to improve the binding used by the backend to interface with LLVM. This binding currently works by producing LLVM assembly code in a temporary file. We want to change this to use the LLVM API instead as this should bring faster compile speeds and allow us to extend the API offered by GHC to include LLVM features. Should all this work go well, hopefully you'll see LLVM become the default backend for GHC in the next major release :)If you feel like looking into any of this in more detail, you can find my thesis paper on the backend here.
- David