Greedy Register Allocation in LLVM 3.0
LLVM has two new register allocators: Basic and Greedy. When LLVM 3.0 is released, the default optimizing register allocator will no longer be linear scan, but the new greedy register allocator.With its global live range splitting, the greedy algorithm generates code that is 1-2% smaller, and up to 10% faster than code produced by linear scan.
Lessons learned from linear scan
Linear scan has been the default register allocator in LLVM since 2004. It has worked surprisingly well for such a simple algorithm. In fact, the simple design made it easier to tweak the algorithm in order to make small improvements to the generated code. More advanced register allocation algorithms often need to build expensive data structures, or they make assumptions about live ranges being invariant. That makes it difficult to, say, commute a two-address instruction on the fly, or rematerialize a constant pool load instead of spilling it to the stack.A new register allocation algorithm needs to preserve this simplicity. It must be possible to change the machine code while the algorithm is running.
Linear scan depends on the virtual register rewriter to clean up the code after registers have been assigned. In theory, the rewriter should only rewrite virtual registers to their assigned physical registers, but it knows many other tricks. When linear scan does something silly like reloading a register from a stack slot twice, the rewriter will clean up the code by reusing the first register and eliminating the second reload. The algorithm is local, and it cannot clean up messes that extend beyond a single basic block. The rewriter always saves the day by removing obvious mistakes. It comes at a high price, though. It accounts for about half of the linear scan compile time, and its large collection of tricks makes the code very hard to maintain.
A new register allocator should avoid making obvious mistakes so the rewriter can concentrate on rewriting registers.
As the name implies, linear scan works by visiting live ranges in a linear order. It maintains an active list of live ranges that are live at the current point in the function, and this is how it detects interference without computing the full interference graph. The active list is the key to linear scan's speed, but it is also its greatest weakness.
When all physical registers are blocked by interfering live ranges in the active list, a live range is selected for spilling. Live ranges being spilled without being split first cause the mess that the rewriter is working so hard to clean up. We would much rather split them into smaller pieces that might be assignable, but this would require the linear scan algorithm to backtrack. This is very expensive, and full live range splitting isn't really feasible with linear scan.
Basic allocator
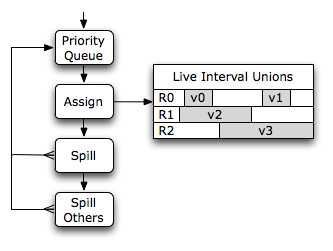
When a live range cannot be assigned to any physical register in its register class, it is spilled. Because live ranges are assigned in order of decreasing spill weight, all the interfering live ranges in the live interval union have a higher spill weight. It is not necessary to look for a better spill candidate.
On CISC architectures, the spill slot memory accesses can often be folded into existing instructions. On RISC architectures, explicit load and store instructions must be inserted. This will also create new tiny live ranges between the spill code and the original instructions using the spilled live range. These new live ranges are put back on the priority queue with an infinite spill weight—they cannot be spilled again.
Technically, these small live ranges with high spill weight should have been assigned first, but the basic allocator never backtracks. Therefore, it can happen that such a live range is blocked by already assigned live ranges with smaller spill weights. In that case, the allocator picks a physical register and spills the interfering live ranges assigned to that register instead.
The basic allocator produces code very similar to linear scan's output, and it also depends on the virtual register rewriter to clean up the code for good results. It doesn't offer significant advantages over linear scan, and it is intended mostly for testing the framework of priority queues and live interval unions. The basic algorithm is very simple, and it offers many opportunities for tweaking. Greedy does just that.
Greedy allocator

Greedy avoids this problem by allocating the large live ranges first. This makes the full register class available for the large ranges, and the small ranges can often fit in the gaps. Some functions have too many large live ranges, so there is not enough room for all the small live ranges. It would be really bad to spill small live ranges with high spill weights, so instead already assigned live ranges with lower spill weight can be evicted from the live range union. Evicted live ranges are unassigned from their physical register and put back in the priority queue. They get a second chance at being assigned somewhere else, or they can move on to live range splitting.
When a live range cannot find interfering live ranges it is allowed to evict, it is not spilled right away. If possible, it is split into smaller pieces that are put back on the priority queue. This is a very important optimization. A large live range may be idle a lot of the time, but used intensively in a hot loop. By creating a separate live range covering the hot loop, there is a good chance it will be assigned a register. The remaining live range may spill outside the loop where it was idle anyway. A live range is only spilled when the splitter decides that splitting it won't help. That usually happens after all the busy regions have been separated, and the remaining live range only has a few copies to and from the busy registers.
The interaction between live range splitting and eviction creates a process of gradual refinement. As live ranges are split around busy regions, they get a higher spill weight. This may allow them to evict older live ranges that are less busy in that region. The evicted ranges are split, and so on.
The gradual process of splitting usually terminates before the live ranges become tiny, and the end result is a set of live ranges covering multiple instructions, or even multiple basic blocks. This means that there is nothing for the rewriter to clean up, and indeed greedy uses a completely trivial rewriter that is 85 lines of code compared to 2600 in the old rewriter.
The code generated by the greedy algorithm is almost always better than what linear scan can do. Usually this is because live range splitting was able to eliminate spill code from loops. Greedy does know some more tricks, though.
Tweaks
It was an important design goal to make the algorithm as flexible as possible, and to avoid introducing arbitrary constraints. It is possible to change machine code and live ranges at any time. Simply evict the relevant live ranges, make the change, and put them back on the queue.This flexibility allows many tweaks to the register allocator:
- Register preferences. Function arguments are passed in specific physical registers defined by the ABI. LLVM represents this with copies between physical and virtual registers before and after function calls. The register allocator tries to assign the virtual registers to the same physical registers, so the copies can be eliminated. Linear scan was never really good at this—the preferred physical register had often been occupied by an earlier assignment. Greedy can simply evict the earlier assignment when that happens.
- Prefer small encodings. On architectures like ARM Thumb2 and x86-64, some registers require a larger instruction encoding. Greedy will evict less important live ranges from the cheap registers before it assigns an expensive register. This means that the larger instruction encodings are used less often, and overall code size decreases.
- Dead code elimination. Optimizations like rematerialization cause live ranges to be shorter, or even completely unused. Greedy will recompute the live ranges exactly, and recursively eliminate dead code.
- Register class inflation. Live range splitting creates virtual registers that are used by fewer instructions. This sometimes lifts a constraint, so the virtual register can be moved to a larger register class. Depending on the architecture, this can double the number of registers available to the new live range.