LLVM relicensing update & call for help
In this blog post, I’d like to summarize the main points I talked about in the relicensing update presentation at the 2021 LLVM Developer’s meeting.
The very short summary is that we are currently in the long tail phase of collecting relicensing agreements of past contributors. We already at the time of this writing have more than 94% of older code relicensed. We hope to crowd source getting through the long tail to get as close to 100% as possible.
Call for help
You can help by looking through the list of remaining individuals and corporations we need to get agreements from, and reaching out to them, or letting us know at license-questions@llvm.org how we can reach out to them. Also, if you’d happen to have any other information that you think could help us, please do let us know at license-questions@llvm.org.
More detailed guidance on how you can help are available at https://foundation.llvm.org/docs/relicensing_long_tail.
In the rest of this blog post, I’m going to give a bit more historical background and describe the current status in more detail.
The LLVM relicensing effort: phases over time
The relicensing effort started some time ago. Let me first very briefly describe the various phases before going in more detail. In the years leading up to 2015, it became clear that there were some issues with the license LLVM had at the time.
A different license was the answer to those issues. Between roughly 2015 and 2017 the focus was on deciding what different license would be best suited.
Once it was decided what the new license was going to be, we started working on getting all code to be covered by this new license. That includes getting agreement from all copyright holders of existing code to share their past contributions under the new license. As you can see on the timeline, getting those agreements is the current focus of the relicensing effort.
Maybe we won’t be able to get an agreement for every single past contribution. In that case, we have a number of options to get to the point where we can claim that all code in the LLVM project is covered by the new LLVM license. We call this phase of relicensing “the end game”.

Why relicense?
The old license consists of 3 components: the UIUC license that covered all the code, the MIT license that additionally covered the code in run-time libraries, and a few sentences on granting patent rights in the developer policy.
This caused the following 3 issues:
Some were blocked from contributing because of the text in the patent section in the developer policy. The wording could be interpreted as requiring giving unnecessarily broad access to patent rights when contributing to LLVM. That made it impossible for some companies to contribute.
The run time libraries were dual licensed under the UIUC and MIT license; the rest of the code only under the UIUC license. Therefore, we could not easily move code to run time libraries from other parts. The reason run time libraries were dual licensed was to enable linking to run time library binaries without requiring attribution to LLVM.
The wording on patent rights in the developer policy was fuzzy and imprecise, leading to uncertainty over whether it did provide the intended protection.
A new license
After exploring a range of options, it was decided that the best solution to solve these issues was to have all code licensed under the Apache-2.0 with LLVM exception license:
Apache-2.0 contains well-understood patent granting which addresses the first and third issue.
The LLVM exception is there for 2 reasons:
It removes a potential incompatibility with using LLVM code in combination with GPLv2 code.
It removes the requirement for developers using LLVM tools to tell the users of the binaries they produce that those binaries may contain some code originating from LLVM. Such a situation can easily arise when parts of the LLVM run-time libraries are linked in as part of the normal compilation process.
The LLVM exception enables the run-time libraries to be covered by the exact same single license as the rest of the code base.
Getting all code covered by the new license
After a decision was made of what the new license should be, we started working on having all code covered by it.
As a first step, we made sure that all new contributions were covered by the new license. This happened after the 8.0 release branch was created. The 100k commits since are covered by the new license.
The remaining task is to also get the earlier contributions covered by the new license. This consists of about 300k commits totaling about 32 million lines of contributed code.
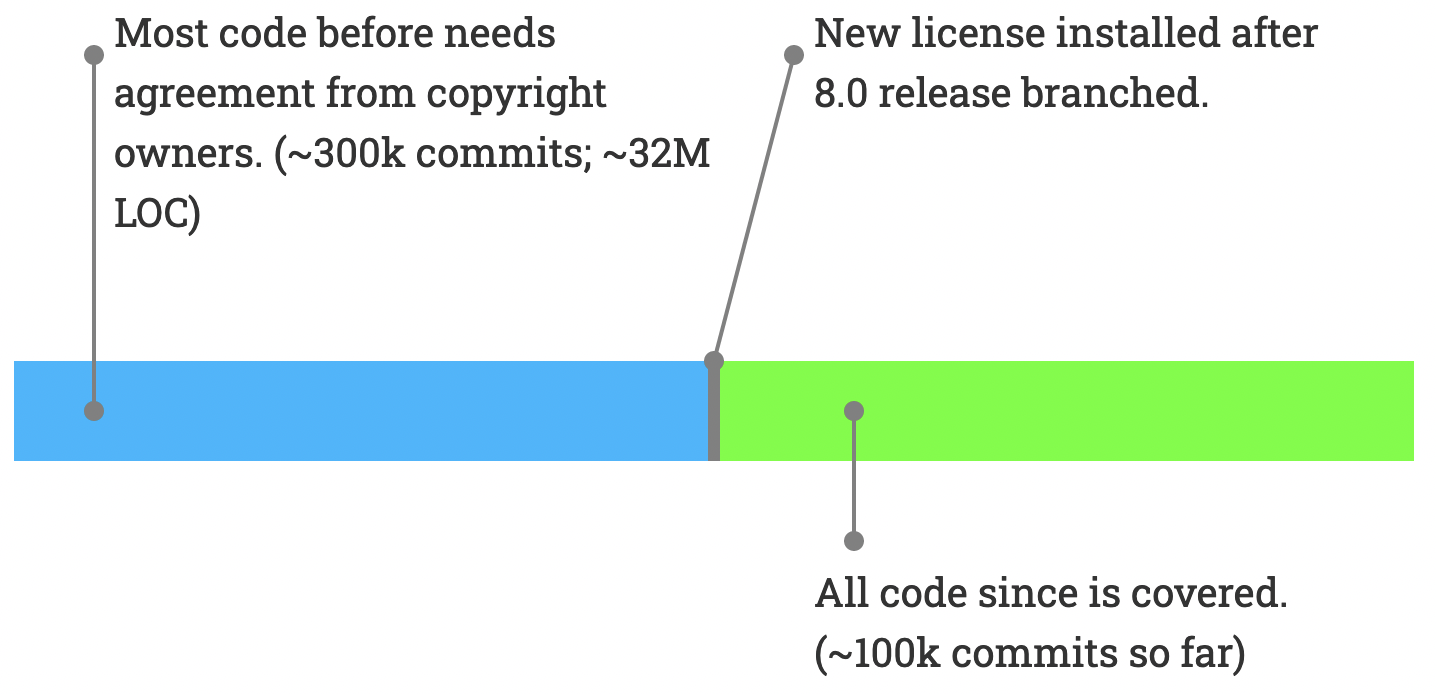
What needs to be done to get those earlier contributions covered?
The reason we need a license in the first place is copyright. Most code contributions are covered by copyright. Which means that the person or company owning the copyright has a lot of decision power over what can legally be done with that code. By covering the code with a license, it becomes clear what others are permitted to do with that code. If there isn’t a license associated with copyrighted code there isn’t all that much useful that others can do with it.
Basically, to get existing code to be covered by a new license, we need to find who owns the copyright on it, and ask them to agree with offering their copyrighted work under the new license.
The copyright owner can be either an individual, for example the person who wrote the code originally; or a company, for example a company that employed the person who wrote the code.
Asking agreement from copyright owners
We started asking for their agreements. By examining the version control log of the 300k-ish commits we need to get agreements for, we found that about 2800 different people or email addresses made a contribution.
We reached out to all of them and asked them two things. First, if any corporation may own the copyright on any of their contributions. Secondly, if they agree with relicensing the contributions they copyright own personally.
So far, we’ve heard of about 220 unique corporations potentially copyright owning some past contribution. We also started reaching out to those, but have not asked every single one just yet.
Status as of November 2021
So after 2.5 years since we started asking – where are we with getting agreements to relicense?
The chart below summarize the current status. It shows a treemap where each rectangle represents the contributions made by one person. The size of each rectangle represents how many lines of code the person contributed.

When the rectangle is green, it means all their contributions are fully covered by relicensing agreements.
When the rectangle is orange, it means we have not yet received such an agreement. When the rectangle is orange with green stars, it means some contributions by that person are covered and others not. This can happen for example when the person has worked for multiple companies over time and only some of those companies have agreed with the relicensing so far.
We already have over 94% of all contributed lines of code between 2001 and 2019 covered by a licensing agreement. We only have a good 5% of lines of code to go still.
As you can see, most of the missing agreements are with “long tail” contributors. By long tail contributors here we mean the many contributors who contributed relatively fewer lines of code. We focussed on reaching out to the bigger contributors first. To reach out well to the long tail of contributors, we’re hoping to get help from the wider LLVM community.
Help wanted!
Please do consider helping us with reaching any of the people or corporations in the long tail. Please have a look at the up-to-date list of people and corporations we can use help with getting in touch with.
You can find more detailed guidance on how you can help on the LLVM foundation website’s relicensing long tail page.
If you do think you could help us with reaching out to someone on the list, or you may have some other information that could help us, please do let us know by emailing license-questions@llvm.org.
Relicensing end game
We are currently in the phase of getting as many relicensing agreements as possible. We do expect that we may not be able to get absolutely 100% of all past contributions covered by an agreement. What can we do to achieve current top-of-mainline to be fully covered by the new license?
We will need to decide on a contribution-by-contribution basis what the options available are to achieve that goal. We have at least the following options.
We can check if copyright even applies to the particular contribution. Very small contributions may not be covered by copyright, and hence may not need a license agreement.
It may well be that code contributed a long time ago is no longer in the code base.
If copyright does apply and the code is still in the code base, we can remove the contribution. Depending on whether current contributors and users still value the effect of that contribution, it may need to be reimplemented.