Adding a new target/object backend to LLVM JITLink
Motivation
For the last year, I have been contributing to LLVM JITLink. This post aims to doubly serve as a summary of my work and documentation for future contributors looking to add a new target/object backend to LLVM JITLink.
We will start by establishing some background and definitions of relevant concepts. Then, we will talk about what the project actually entailed. Finally, we will go over the execution details of the project.
The end goal of the project was to make LLVM JITLink capable of linking a 32-bit ELF object file, with i386 specific relocations, into a 32-bit process on the i386 hardware architecture.
If the goal of the project already makes sense to you and you are looking to get started with adding a new target/object backend to LLVM JITLink yourself, you can skip to the “Recap and conveniences” section.
Background
Linking
Our code often relies on external dependencies. For example, even a simple hello-world program written in C depends on the C stdlib for the printf function. These external dependencies are expressed as symbolic references, which I will henceforth refer to as just symbols. Symbols are names of data or functions that have unknown addresses and are resolved or fixed up during the linking process.
In chronological order -
- The compiler converts source code to machine code.
- The assembler converts machine code to object files (ELF, MachO, COFF etc.)
- The linker links one or more object files (fixing up symbolic references along the way) and produces an executable or a shared library (also called shared object or dylib).
For the purposes of this discussion we will focus on executables, but the points that will be made hold for shared objects as well.
JIT linking
Unlike static linking, JIT (Just-in-time) linking is performed at runtime. While a static linker produces executables that are stored on disk, a JIT linker produces an in-memory image of the executable – essentially ready to execute bytes in memory. JIT linking a C program may feel very much like running a shell script. Under the hood though, the C program is linked into the memory of the invoking process, also commonly referred to as the executor process. The JIT linker patches up the executor process’ memory to account for the addresses of symbols at runtime, and executes necessary initializers.
If you are familiar with dynamic loading then JIT linking may sound familiar, and the two have a lot in common, however they are not the same. JIT linking operates on relocatable objects (vs shared objects/dylibs for dynamic loading), and performs both the static linker’s and the dynamic loader’s jobs. Doing so allows the JIT linker to dead-strip redundant symbols, which dynamic loading cannot do, and this allows JIT linking to support finer grained compilation of languages that tend to produce a lot of redundant symbol definitions(e.g. C++).
Need for JIT linking
JIT linking is primarily useful in the context of pre-compiled languages, such as C, C++, Rust etc. Why? At run time, these languages have no way1 to bring new symbol definitions into a running process’ memory and resolve references to them. Although dynamic loading partially solves this issue, it has its drawbacks (discussed above) and lags far behind the static linking experience.
With JIT linking, at run time, symbolic references can be resolved to existing symbols (from the newly JIT’d code), or to newly JIT’d symbols (from the pre-compiled code). The below toy example shows what this looks like in code.
// Let's assume we have the following, rather contrived,
// C++ program that wants to add 2 numbers, but wants to use
// an `add` function from a relocatable object file supplied by
// the user.
//
// Let's also assume that the add function in the user-supplied
// relocatable object will reference a symbol named `MAGIC` in its
// definition.
const int MAGIC = 42;
int main(int argc, char* argv[]) {
int a = 1;
int b = 2;
// Read the path of the user supplied relocatable object.
string userSuppliedObjectPath = ...;
// Initialize your JIT class that uses JIT linking under the hood.
JIT J;
// Add the relocatable object to your JIT.
J.addObject(userSuppliedObjectPath);
// Lookup the `add` function in the newly added JIT object.
// Once all symbolic references within the user supplied object
// are resolved, the content is fixed up and emitted to memory.
// And we can then get a pointer to the `add` function.
auto *add = (int(*)(int, int))J.lookup("add").getAddress();
// At this point the symbolic reference to `MAGIC` in add's
// definition must have been resolved to the memory address
// of the constant `MAGIC` that we defined in this program.
// Run the add function found in the JIT module.
int result = add(a, b);
}
That said, JIT linking by itself is not something that is very useful for an end user. JIT linking is an enabler for certain use-cases with pre-compiled languages (some use-cases exist for JIT-compiled languages as well2).
- JIT compilers (think of something like the JIT compilation component of the Java Hotspot VM, but for a statically compiled language)
- Debugger expression evaluators (such as the LLDB expression evaluator)
- REPLs (such as Cling and the currently experimental3 Clang-REPL)
- Standalone scripts (such as the Swift scripts, where the JIT linking is used to add an immediate mode to the compiler, which runs your code in-place via a JIT, rather than compiling it)
- Scriptable extensions (think about running JIT’d code in the context of some existing app, allowing the app to be extended by JIT’d code rather than precompiled plugins)
While the above use cases may seem different, they are really the same — JIT linking enables linking code into existing processes (that may or may not already contain state/context), in an ABI-compatible way.
LLVM JITLink
LLVM JITLink is a JIT linking implementation, in the form of a low-level library within the LLVM infrastructure. It powers LLVM’s ORC JIT APIs, which is what end-users would usually use for building runtime linking environments. It provides primitives for:
- Re-using existing compilers to generate relocatable objects at runtime.
- Allocating memory within a target executor process.
- Linking code into a target executor process in an ABI-compatible way.
In simple words, a program Y, running in a process X, can hand JITLink a relocatable object file and JITLink will link the object file’s code into X’s memory and run it under X’s existing context (globals, functions etc.), as if it were part of a dynamic library loaded into process X4.
The project
Having set up all that background, let’s understand the main task and the end goal of the project.
The task - Adding the i386(target)/ELF(object)backend to JITLink
- What is a target?
- Target here, refers to a hardware architecture. i386 is a 32 bit x86 architecture.
- What is an object?
- Object here, refers to an object file format. ELF is the object format commonly used on Linux systems.
- Why do different target/object combinations matter and need additional work?
- Different target/object combinations matter, because each combination may use distinct methods for connecting symbolic references to symbol definitions. These methods are commonly referred to as relocations.
The end goal
The end goal of the project was to make LLVM JITLink capable of linking a 32-bit ELF object file, with i386 specific relocations, into a 32-bit process on the i386 hardware architecture.
Execution
Understanding high level constructs
LinkGraph
The LLVM JITLink documentation has an excellent description of LinkGraph. I recommend reading it after the below, high-level description of LinkGraph.
LinkGraph is an internal representation of an object file within LLVM JITLink. While object formats may have different schemas and terminology for similar concepts, they all aim to represent machine code that can be relocated in virtual memory. The purpose of a LinkGraph is to provide a generic representation of these concepts and nuances across different object file formats.
To draw conceptual analogies between the LinkGraph and an object format, let’s use ELF as an example. An ELF object contains:
- Sections - Any chunk of bytes that must be moved into memory as a unit.
- Symbols - A named chunk of bytes that could represent either data or executable instructions. Symbols occur as children of sections.
- Relocations - A description of how to fix up bytes within a section once the address of the relocation’s target symbol is resolved.
A LinkGraph is capable of representing all of the above concepts. It first defines some building blocks.
- Addressable - Anything that can be assigned an address in the executor process’ virtual address space.
- Block - A chunk of bytes that is addressable and occurs as part of a section.
On top of these building blocks, it defines the higher level object format concepts.
- Symbol - Equivalent of a symbol in the ELF format. Represented using an offset from the base (address) of a Block and a size in bytes.
- Section - Equivalent of a section in the ELF format. Represented using a collection of symbols and blocks.
- Edge - Equivalent of a relocation in the ELF format. Represented using an offset from the start of the containing block (indicating the storage location that needs to be fixed up), a pointer to the target whose address needs to be used for the fix-up and a kind to specify the patching formula.
JITLinkContext
JITLinkContext represents the target process that you’re linking into, and it provides the JIT linker with the ability to ask questions about and take actions within the process. This includes the ability to look up symbols and allocate memory, in the target process, as well as to publish the results of the linking process to the broader environment. Specifically, the JITLinkContext informs others of the addresses it has assigned to symbols and when those symbols become available in memory.
Understanding the JIT linking algorithm
The LLVM JITLink linking algorithm happens in multiple phases, with each phase consisting of passes over the LinkGraph and a call to the next phase at the end. In each phase the algorithm modifies the LinkGraph as needed, by the end, producing a ready to execute in-memory image of the relocatable object that we started out with.
Something that did not click for me initially, but simplified things significantly once it did, was the fact that the LinkGraph was just that, a graph! Re-reading LLVM JITLink’s high-level description of the generic JIT linking algorithm with this simple view of the LinkGraph made it much easier and intuitive to make sense of what was going on in the JIT linking process.
The algorithm also provides, implementers and users of JITLink, hooks to tap into the linking process. These hooks can be used to achieve a number of things, including but not limited to, link-time optimizations, testing, validation etc.
The tangibles
First, I set up a test loop to validate whether LLVM JITLink is able to link 32-bit i386 ELF objects, containing valid i386/ELF relocations, into a 32 bit process. The existing llvm-jitlink tool, which is built and put into the bin folder by default when you build the LLVM project, came in handy. llvm-jitlink is a command line wrapper for the JITLink library. It takes relocatable objects as input and links them into the executor process using JITLink.
The tricky part here, at least for me, was to get a 32-bit llvm-jitlink ELF executable. By default, Clang produces executables for the host architecture because of which I had to understand cross-compilation5 (compiling for a target different from the host architecture) since I was developing on x86-64 hardware. In order to obtain a 32-bit llvm-jitlink ELF executable, on an x86-64 system, I needed the following -
Cross-compiler - A cross-compiler that could generate 32 bit x86 code. Clang generates 32-bit x86 code if the following flags are specified in the build configuration:
CMAKE_CXX_FLAGS="-m32"orCMAKE_C_FLAGS="-m32"- instructs Clang to generate 32-bit code instead of the default 64-bit code.LLVM_DEFAULT_TARGET_TRIPLE=X86- instructs Clang to generate machine code for the x86 target by default.
Target shared libraries - 32 bit x86 shared libraries, that might be checked against during compilation. In my case installing
libstdc++.i686andglibc-devel.i686sufficed since that is all I needed to generate programs containing all possible i386/ELF relocations.
The full command that I used to generate my build configuration was -
cmake -DCMAKE_CXX_FLAGS="-m32" -DCMAKE_C_FLAGS="-m32" \ -DCMAKE_CXX_COMPILER=<PATH_PREFIX>/bin/clang++ \ -DCMAKE_BUILD_TYPE=Debug \ // It is important that the `llvm-tblgen`executable is for the host architecture -DLLVM_TABLEGEN=<LLVM_BUILD_DIR_FOR_HOST_ARCH>/bin/llvm-tblgen \ -DLLVM_DEFAULT_TARGET_TRIPLE=i386-unknown-linux-gnu \ // Set of targets that the compiler must be able to generate code for. // Can save compilation time by omitting redundant target backends. -DLLVM_TARGETS_TO_BUILD=X86 \ -G "Ninja" ../llvm
The last piece of my test loop was the plumbing in LLVM JITLink, on top of which I could start adding i386/ELF relocations. I added this plumbing as part of my first commit to LLVM JITLink. At a high level, there were 2 things that I implemented in that commit -
- ELFLinkGraphBuilder_i386 - contained specialized logic for parsing i386/ELF relocations from an object file.
- ELFJITLinker_i386 - contained specialized logic for fixing up i386/ELF relocations in the executable image supposed to be emitted to memory.
Having set up a test loop, I incrementally added support for the following i386/ELF relocations to LLVM JITLink.
Quick aside, before we talk about the individual relocations! Let’s recall what relocations are.
The compiler generates code which contains symbolic references to actual symbols (everything other than local variables in a function and functions themselves). The compiler just refers to symbols by the names used by the programmer and leaves a set of TODOs for the linker to complete during linking.
In ELF objects, these TODOs are found in the relocation section. They tell the linker where and how a symbolic reference needs to be fixed. The linker then, for the most part, follows the compiler’s instructions and resolves all the relocations in the program. The linker can resolve relocations because it has a view of the entire compiled program.
- R_386_32
- What - Tells the linker to replace the symbolic reference with the symbol’s absolute memory address.
- When - Used to reference global and static variables in non position-independent code (PIC). PIC allows code to be loaded at any address in memory, rather than at a fixed address.
- Code -
// Compile with => clang -m32 -c -o obj.o obj.c // declare a global variable x int x; int main() { // Compiler should generate a R_386_32 relocation here. x += 1; return 0; }00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 50 push %eax 4: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%ebp) // Compiler wants to move the value of x into // the eax register but doesn't know the address // of x. So it leaves a TODO for the linker and // temporarily uses 0 as x's address. b: a1 00 00 00 00 mov 0x0,%eax c: R_386_32 x 10: 83 c0 01 add $0x1,%eax // Same thing here 13: a3 00 00 00 00 mov %eax,0x0 14: R_386_32 x 18: 31 c0 xor %eax,%eax 1a: 83 c4 04 add $0x4,%esp 1d: 5d pop %ebp 1e: c3 ret
- R_386_PC32
- What - Tells the linker to resolve the symbolic reference using the symbol’s relative offset to the current program counter (PC). The linker finds the offset of the referenced symbol, relative to the PC and hard-codes it in the corresponding assembly instruction. At run time, the processor looks at the call instruction’s encoding and knows that the operand to the instruction represents the symbol’s offset to the PC.
- When - Used to call functions in PIC.
- Code -
// Compile with => clang -m32 -ffunction-sections -c -o obj.o obj.c // declare a global function x void x {} int main() { // Compiler should generate a R_386_PC32 relocation here. x(); return 0; }00000000 <x>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 5d pop %ebp 4: c3 ret 00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 83 ec 08 sub $0x8,%esp 6: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%ebp) // Compiler wants to call function x // but doesn't know its address. So it leaves // a TODO for the linker and temporarily uses garbage // bytes as x's address. // // The linker will replace the garbage bytes 0xfffffffc // with `offset => PC - address of x`. // `e8` here tells the i386 processor that the operand // is a PC relative offset and that the address of x needs // to be computed using `PC + offset` d: e8 fc ff ff ff call e <main+0xe> e: R_386_PC32 x 12: 31 c0 xor %eax,%eax 14: 83 c4 08 add $0x8,%esp 17: 5d pop %ebp 18: c3 ret
Another short detour to talk about dynamic linking because the remaining relocations are what enable dynamic linking.
In static linking, if your program accesses even a single symbol from a given library, then that entire library is linked with your program, which among other issues, increases the size of the generated executable. For instance, let’s talk about that simple C program that just prints hello world again. With static linking, the executable that’s generated from your program is going to pull in the entire C standard library, because your program accessed the printf function.
In dynamic linking, referenced libraries are accessed at build time but they are not brought into the linked executable. Instead, the referenced global variables from these libraries are linked at load time (when the program is loaded into memory, to be run) and referenced functions from these libraries are linked at invocation time.
There’s pros and cons to both approaches, whose details I will not go into, but will cursorily mention below.
With static linking the only thing the user of your executable needs is the executable itself. They won’t run into issues of missing libraries.
With dynamic linking you don’t need to update your executable, if the shared library is updated. This is especially useful if you are distributing your executable.
Dynamic linking is just harder to implement than static linking.
If you’re not already familiar with the concepts of GOT and PLT, I also recommend you take yet another quick detour for some visual explanations!
- R_386_GOTPC -
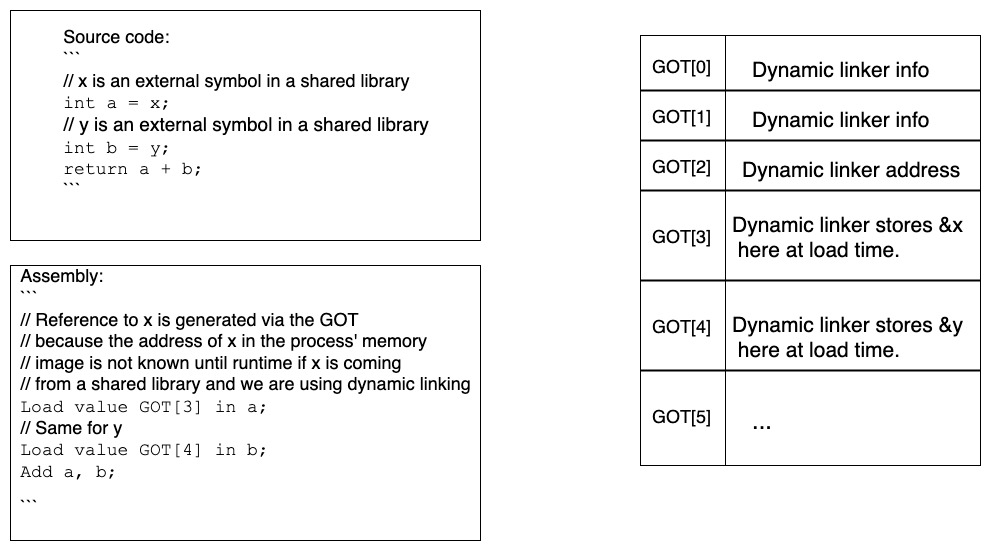
- What - Tells the linker to replace the symbolic reference with the delta between the storage location, where the relocation has to be applied (or the fixup location) and the address of the GLOBAL_OFFSET_TABLE (GOT) symbol.
- When - This relocation isn’t used in isolation. Rather it is an enabler for R_386_GOTOFF, R_386_GOT32 and R_386_PLT32, which need to use the memory address of the GOT.
- Code -
// Compile with => clang -m32 -fPIC -c -o obj.o obj.c // Declare a global static static int a = 42; int main() { // Since we passed the `PIC` flag to Clang to // indicate that we want position independent code // Clang will generate code to access `a` using // the GOT. return a; }00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 50 push %eax // This `call` instr is just telling the processor to // push the next instr's address on the stack and jump to // address 9. But 9 is the address of the next line. That's // weird... 4: e8 00 00 00 00 call 9 <main+0x9> // And now that we did jump to 9, all we did was pop // the value that was on the stack and store it in ebx. // Wasn't the value on the stack just 9's address? Even // weirder... 9: 58 pop %ebx // Wait a minute. The compiler left a TODO here for the // linker, to find the delta between the fixup location // and the address of the GOT. // // Ok, so if the address of the GOT was let's say 20, // then the linker will try to hardcode the value // `0x20-0xc => 0x14` and add it to the value in eax (0x9), // which will give us `0x14 + 0x9 => 0x1d`. // // Ah, that's not the address of the GOT. Yes, but // `0x1d + 0x3 => 0x20` is. Well, where is the 3 coming from? // The compiler helps us here, a bit. The address in eax isn't // the address of the fixup location it's off by 0x3. So along // with leaving us a TODO, the compiler also leaves us a reminder // to add 0x3 to our delta calculation, in order to arrive at // the correct address of the GOT. a: 81 c0 03 00 00 00 add $0x3,%ebx c: R_386_GOTPC _GLOBAL_OFFSET_TABLE_ // Not super important what happens after the R_386_GOTPC // relocation is resolved for now...
- R_386_GOTOFF -
- What - Tells the linker to resolve the symbolic reference with the offset between the symbol’s address and the address of the GOT’s base (computed and stored in a register when the R_386_GOTPC relocation is handled).
- When - Used by shared libraries and executables to access internal symbols in a position independent way.
- Code -
// Compile with => clang -m32 -fPIC -c -o obj.o obj.c // Declare a global static static int a = 42; int main() { // Since we passed the `PIC` flag to Clang to // indicate that we want position independent code // Clang will generate code to access `a` using // the GOT. return a; }00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 50 push %eax 4: e8 00 00 00 00 call 9 <main+0x9> 9: 58 pop %eax // We saw above how the R_386_GOTPC relocation gets resolved // and that the ebx register contains the address of the // GOT after the relocation is resolved. a: 81 c0 03 00 00 00 add $0x3,%ebx c: R_386_GOTPC _GLOBAL_OFFSET_TABLE_ 10: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%ebp) // Compiler wants to access `a`, but since we told it // to generate position-independent code, it generates access // to `a` using the GOT and leaves a TODO for the linker to find // the offset of `a` from the base of the GOT. // // The linker already knows the address of the base of the GOT // at this point - it's stored in ebx. It computes the address of // `a` and fixes up the 4 bytes after `0x8b 0x80`, to store the // offset between `a` and the GOT's base. 17: 8b 80 00 00 00 00 mov 0x0(%ebx),%eax 19: R_386_GOTOFF a 1d: 83 c4 04 add $0x4,%esp 20: 5d pop %ebp 21: c3 ret
- R_386_GOT32
- What - Tells the linker to resolve the symbolic reference with the offset between the address of the GOT’s base and the symbol’s entry in the GOT (essentially computing an index into the GOT).
- When - Used by shared libraries and executable to access external data symbols in a position independent way.
- Code -
// Compile with => clang -m32 -fPIC -c -o obj.o obj.c // Declaring that `a` is defined externally. extern int a; int main() { // Since we passed the `PIC` flag to Clang to // indicate that we want position independent code // Clang will generate code to access `a` using // the GOT. return a; }00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 50 push %eax 4: e8 00 00 00 00 call 9 <main+0x9> 9: 59 pop %ecx // We saw above how the R_386_GOTPC relocation gets resolved // and that the ebx register contains the address of the // GOT after the relocation is resolved. a: 81 c1 03 00 00 00 add $0x3,%ebx c: R_386_GOTPC _GLOBAL_OFFSET_TABLE_ 10: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%ebp) // Compiler wants to access `a`, but since we told it to // generate position-independent code, it generates access to // `a` using the GOT and leaves a TODO for the linker to find // the offset of `a`'s GOT entry from the base of the GOT. // // `a` got a GOT entry because we did not define it internally // and the compiler thinks that it will either come from another // source file or a shared library. // // The linker already knows the address of the base of the GOT // at this point - it's stored in ebx. It finds the address of // `a`'s GOT entry and fixes up the 4 bytes after `0x8b 0x81`, // to store the offset between `a`'s GOT entry and the GOT's base. 17: 8b 81 00 00 00 00 mov 0x0(%ebx),%eax 19: R_386_GOT32 a // eax, at this point contains `a`'s address, which is dereferenced // in this mov instruction and stored into eax itself. 1d: 8b 00 mov (%eax),%eax 1f: 83 c4 04 add $0x4,%esp 22: 5d pop %ebp 23: c3 ret
- R_386_PLT32
- What - Tells the linker to resolve the symbolic reference with the symbol’s PLT entry.
- When - Used by shared libraries and executables to access external function symbols in a position-independent way.
- Code -
// Compile with => clang -m32 -fPIC -c -o obj.o obj.c // Declaring that `foo` is a function defined externally. extern int foo(void); int main(void) { // Since we passed the `PIC` flag to Clang to // indicate that we want position independent code // Clang will generate code to access `foo` using // the PLT. return foo(); }00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 53 push %ebx 4: 50 push %eax 5: e8 00 00 00 00 call a <main+0xa> a: 5b pop %ebx // We saw above how the R_386_GOTPC relocation gets resolved // and that the ebx register contains the address of the // GOT after the relocation is resolved. b: 81 c3 03 00 00 00 add $0x3,%ebx d: R_386_GOTPC _GLOBAL_OFFSET_TABLE_ 11: c7 45 f8 00 00 00 00 movl $0x0,-0x8(%ebp) // Compiler wants to access `foo`, but since we told it to // generate position-independent code, it generates access to // `foo` using its PLT entry and leaves a TODO for the linker to // find `foo`'s PLT entry address. // // The PLT machinery was explained here! 18: e8 fc ff ff ff call 19 <main+0x19> 19: R_386_PLT32 foo 1d: 83 c4 04 add $0x4,%esp 20: 5b pop %ebx 21: 5d pop %ebp 22: c3 ret
Testing
While I did talk about setting up a “test loop” earlier, here I want to briefly touch upon the topic of regression tests – not so much upon the “why” and the “what”, but the “how”. There’s some excellent testing utilities already available in the LLVM project, but I found related documentation to be lagging. Specifically, I want to focus on the utilities that one might interact with for writing a regression test for one of LLVM JITLink’s target-object backend.
Before we go ahead, I want to mention this high level testing guide for LLVM. The guide should get you to the point where you know where/how to create a test file, how to make your tests discoverable by the test runner (LLVM Integration Tester - lit) and how to run the tests using the test runner.
That said, let’s use the sample test file below, to talk about the utilities that you might use for writing a regression test for one of LLVM JITLink’s target-object backend.
// Regression test files are assembly files (".s" extension).
// The files must begin with what are known as "RUN" lines.
// Each "RUN” line tells lit how to run the test file.
// RUN lines look and feel like you were running shell commands.
// Each regression test will likely begin with the following
// two RUN lines, although the exact RUN command may need to be
// modified, based on the test cases need.
# RUN: llvm-mc -triple=i386-unknown-linux-gnu -position-independent -filetype=obj -o %t.o %s
// Notice how llvm-jitlink is run with the "-noexec" option.
// The option tells llvm-jitlink to not run the code loaded
// to memory. This is important because JITLink may be linking
// and loading code for an architecture different from the one
// where the regression test is running in LLVM's build/release
// pipeline.
# RUN: llvm-jitlink -noexec %t.o
// llvm-jitlink also requires each file to have a "main" function.
// Your test code can go here, but it doesn't have to.
.text
.globl main
.p2align 4, 0x90
.type main,@function
main:
ret
.size main, .-main
The main thing that we want to determine in these target-object backend regression tests is whether the relocations in the code emitted to memory were fixed up correctly. Meaning, we have to literally check whether certain bytes in certain memory locations are what we expect them to be. Let’s look at some more intricate test cases that will show the different kinds of checks we might need to perform and how we can perform them.
// llvm-jitlink allows you to specify jitlink-check expressions.
// jit-link check expressions are checks against working memory.
// jit-link check expressions can be used with the `decode_operand` function.
// `decode_operand` decodes the instruction at the given label
// and then accesses the operand number that you have specified.
//
// For the expression below, decode operand decodes the operand at the
// label `foo`, accesses its 0th operand `external_data` and checks whether
// its value is equal to the bytes represented by `0xDEADBEEF`.
//
// Note - The operand number does not always have a one-to-one mapping
// with what you see and while in this case `external_data` was indeed the
// 0th operand of the instruction, for another instruction its operand
// number may have been different.
# jitlink-check: decode_operand(foo, 0) = 0xDEADBEEF
.globl foo
.p2align 4, 0x90
.type foo,@function
foo:
movl external_data, %eax
.size foo, .-foo
// The RHS of jitlink-check expressions doesn't have to be literal
// bytes. It can be an expression of labels and other functions over
// labels.
//
// In the below jitlink-check expression, the RHS
// is calculating the difference between the address of the label
// `foo` and the address of the program counter when the instruction at label
// `bar` is executed.
# jitlink-check: decode_operand(bar, 0) = foo - next_pc(bar)
.globl bar
.p2align 4
.type bar,@function
bar:
calll foo
.size bar, .-bar
// The `got_addr`function can also be used on the RHS, to access the
// address of the GOT entry of a symbol.
//
// In the below jitlink-check expression, the RHS is calculating the
// offset between the GOT entry for the symbol `named_data` and the
// GOT symbol itself.
# jitlink-check: decode_operand(test_got, 4) = got_addr(test_file_name.o, named_data) - _GLOBAL_OFFSET_TABLE_
.globl test_got
.p2align 4, 0x90
.type test_got,@function
test_got:
leal named_data@GOT, %eax
.size test_got, .-test_got
// The LHS of a jitlink-check expression, can also be constructed manually
// by "casting" a symbol, label or a function over a label to a machine register
// size pointer.
//
// In the below jitlink-check expression the LHS is constructed by casting the
// address of the GOT entry for `named_data` to a 32-bit pointer. The constructed
// pointer is then dereferenced and compared against the `named_data` label.
# jitlink-check: *{4}(got_addr(test_file_name.o, named_data)) = named_data
.globl test_got
.p2align 4, 0x90
.type test_got,@function
test_got:
leal named_data@GOT, %eax
.size test_got, .-test_got
// NOTE - The above presented flavors of jitlink-check expressions is not an
// exhaustive list of what's available. Rather it's just a summarization of some
// of the ways in which I used jitlink-check expressions.
Recap and conveniences
We covered a lot of ground there. Let’s quickly recap the things we talked about.
- We established the context required to understand the project. We defined basic concepts - linking and JIT linking, and talked about the need for JIT linking and LLVM JITLink.
- We established an understanding of what the project was.
- We went over the execution details of the project. We talked about important high level constructs, the high level JIT linking algorithm used by LLVM JITLink, setting up a testing loop for constant feedback and the details of each relocation that was added as part of the i386/ELF backend.
- Finally, we talked about the tools and utilities that can be used to write regression tests for the project.
Resources
Below is an index of resources that I found useful (I may have mentioned them elsewhere in the post as well).
- Chris Kanich’s videos for the systems programming course at University of Illinois, Chicago
- Lang Hames’ videos (1, 2, and 3) on LLVM ORC APIs and JITLink. These videos were extremely valuable in understanding JITLink’s raison d’être and the context in which it is used.
- Linkers and Loaders by John R. Levine
- Oracle’s Linker and Libraries guide
- LLVM JITLink documentation
- LLVM testing infrastructure guide
- Articles by Eli Bendersky on position-independent code and load time relocation of shared libraries.
Development conveniences
- Dev setup
- There’s detailed information about that on the getting started with LLVM page.
- If you’re okay using AWS EC2 for development you can create an instance using my public machine image.
- The image id is ami-00f1c534fe06c05a0. You can use the instructions here to boot your instance using this image.
- The instance comes with all the basic tools and softwares that you need to start contributing to LLVM - Clang, CMake, Python, zlib, ninja, git, php, arc.
- Build system
- Use
ninja! It is way faster thanmake. - If you want to build a
llvm-jitlinkbinary, which you likely will for testing, just runninja llvm-jitlinkfrom your build folder’s root. This will avoid building other targets that you do not need and will complete much faster. - Other than that I’m going to refrain from saying too much here because one’s build system configuration rarely works on another’s machine.
- Use
- Files you will be dealing with
- You’ll likely be dealing with files under llvm/lib/ExecutionEngine/JITLink.
- The introductory commit for the i386/ELF and AArch64/ELF backends will give you a very good idea of what a minimal backend implementation looks like. Keep in mind that these first commits are for backends for an existing object format (ELF in this case). If you are adding support for a backend without an existing object format, you might need to ask for help (more on that in a bit).
- Code reviews
- Install arcanist - the tool for creating code reviews when contributing to LLVM.
- Once installed the main commands you will be using are (assuming you are using git as your version control) -
- arc diff - To create code reviews and new revisions.
- arc land - To close code reviews once they are approved and push changes to remote.
- Asking for help
- #jit channel of the LLVM discord server.
Closing thoughts
And that’s about it! I don’t have too much more to say on top of what’s already been said. It was a great learning experience contributing to LLVM JITLink. I’d recommend it to anyone who wants to understand the story after compilation and up until a program is run - come say hi on the #jit channel of the LLVM discord server!
I’d also like to give a big shout out to the folks on the #jit channel for helping me understand things and answering my questions. And a special thanks to Lang Hames for his help throughout the project and reviewing this post (thanks to Stefan Gränitz and Vassil Vassilev for reviewing as well)!
I plan on continuing my involvement with LLVM and JITLink, and am excited to see what I pick up next!
Appendix
What are GOT and PLT?
The GLOBAL_OFFSET_TABLE (GOT) and PROCEDURE_LINKAGE_TABLE (PLT) are 2 tables used during the linking process that make dynamic linking work. Dynamically linked code needs to be position-independent6, meaning that it should be able to be loaded at any address in memory and continue to work - all symbols that it references and all referenced symbols that it contains, must be resolvable. Dynamically linked shared libraries can fulfill this position independence requirement for internal symbols using pc-relative addressing, as the code of the shared libraries stays together in memory. However, these libraries may also refer to external symbols or contain symbols, referenced by other shared libraries or the main executable. And since the load address of shared libraries, in memory, is not fixed, they require another layer of abstraction for the resolution of external symbols, for both data and functions. GOT and PLT are those abstractions.
Below are some simple visual examples to understand the GOT and PLT.
- Data symbol access through GOT
Function symbol access through PLT
At load time
- Call to x is generated via the PLT.
- There is also an entry for x in the GOT, whose purpose will become clear in a minute.
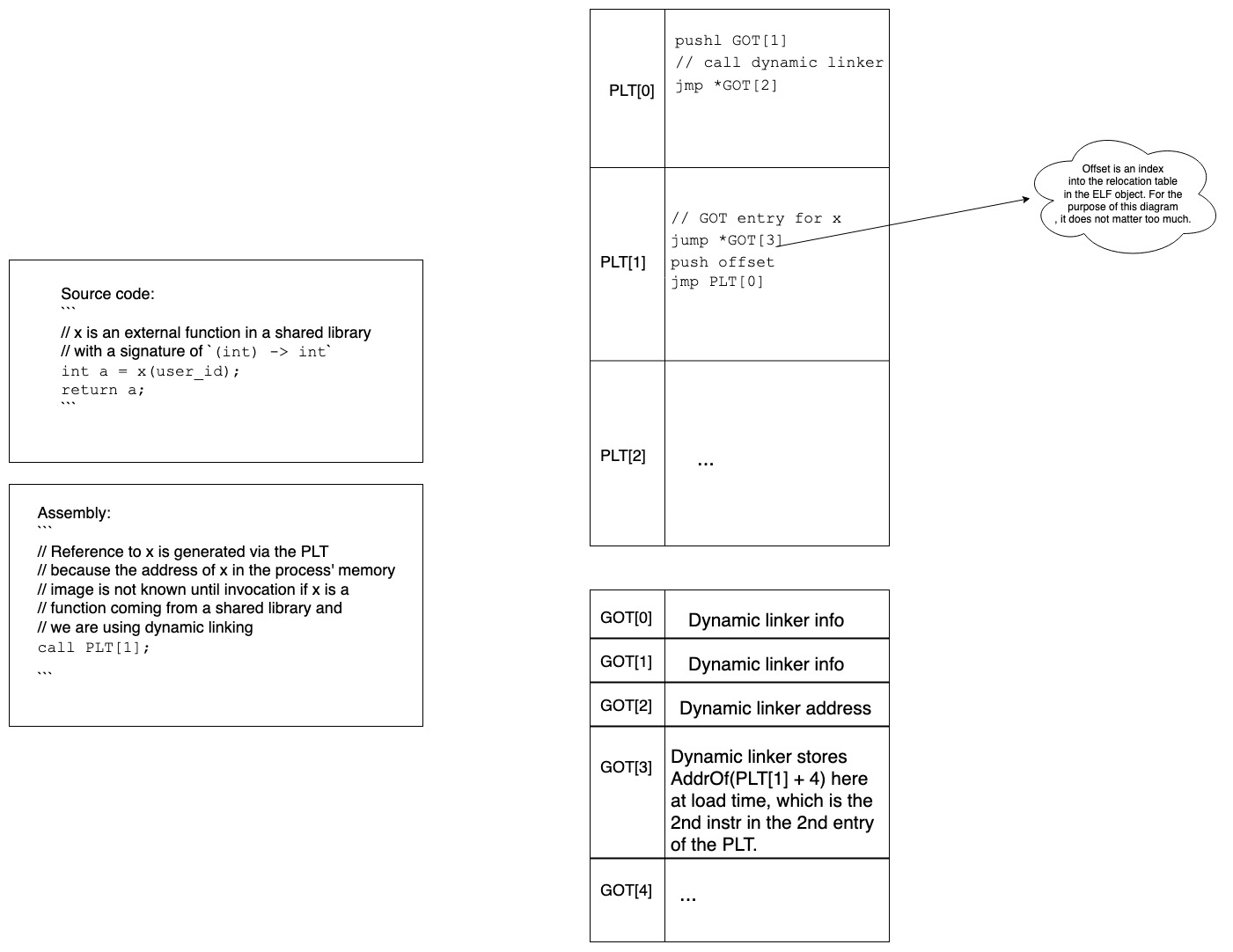
At first invocation time
- Control jumps to PLT[1]
- First instr of PLT[1] transfers control to *GOT[3] (the address stored in GOT[3]).
- Remember the address stored in GOT[3] is that of the 2nd instr of PLT[1].
- Wait, so we go all the way to the PLT, to then go all the way to the GOT only to come back to the next instr in PLT[1]. We would have come there anyways as the processor processed instructions sequentially. Why did we take this roundabout route?
- We’ll see in a second!
- Once we’re on the 2nd instr of PLT we push a value on the stack (what this value means is not super important here).
- Then control jumps to PLT[0], from where you can see it eventually jumps to the address stored in GOT[2].
- And whose address is stored in GOT[2]? The dynamic linker’s!
- The dynamic linker then goes ahead and links x (the external lib function we called) into the process and fixes the address in GOT[3] (which was initially the address of the 2nd instr of PLT[1]) to the new address of x in the process.
- The dynamic linker then invokes x, which is what the user wanted to do in the first place.
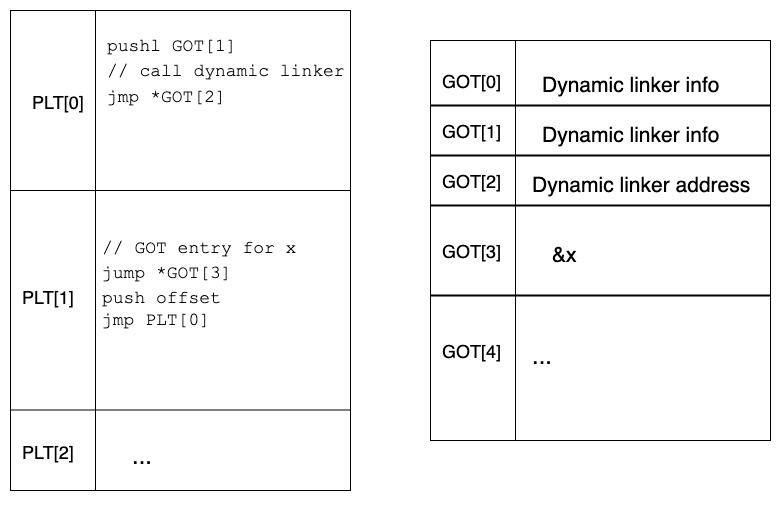
- Subsequent invocations
- The first invocation of x looked like this -
- PLT[1] → *GOT[3] → PLT[1] → PLT[0] → *GOT[2] → x()
- However, since the dynamic linker now fixed the entry in GOT[3] to reflect x’s address, subsequent invocations of x look as below -
- PLT[1] → *GOT[3] (which is essentially calling x, since that is what GOT[3] stores now)
- The first invocation of x looked like this -
With the above process dynamic linking enables us to call a functions in position-independent code. Additionally, it makes the common case (every invocation of x other than the first) faster!
Footnotes
AOT, statically compiled languages - C, C++, Rust, unlike interpreted languages, such as Java, do not have a runtime that can be extended to bring in new symbols at runtime and perform symbol resolution for them. Java, for instance, has the Java Virtual Machine (JVM) whose loading and linking behavior can be customized to achieve the aforementioned task. ↩︎
JIT-linking is primarily useful in the context of linking in pre-compiled languages (that’s certainly what inspired it), but it’s not only useful in that context. In LLVM JITLink, through the JITLinkContext you can link against other (non-statically compiled) code, so it’s useful for anyone who wants to interoperate with C/C++ that’s linked at runtime. You could also theoretically bring up a purely JIT’d language with it (and I think Julia does this). The advantages are interoperability with existing languages, compilers, tools, and the disadvantage is that it’s heavyweight compared to a custom JIT that manages its own linking directly. ↩︎
Clang-REPL is an effort to move Cling, which is a standalone tool, into the LLVM infrastructure. ↩︎
In fact, given a suitable JITLinkContext, JITLink can even link objects into a different process. LLDB uses this capability (via LLVM’s older MCJIT APIs) to JIT-link expressions in the debugger, but run them in the process being debugged, which may be on a different machine. ↩︎
I found the following 2 resources very useful for understanding cross-compilation.
- “Cross-platform Compilation” chapter of the Getting Started with LLVM Core Libraries book.
- Clang documentation for cross-compiling.
Dynamically linked code can actually use the “static” relocation model, but the position-independent model is generally preferred. In position-independent code you only need to fix up the GOT, whereas in static code you need to fix up every external reference, which can hurt launch times. ↩︎