GSoC 2024: Reviving NewGVN
This summer I participated in GSoC under the LLVM Compiler Infrastructure. The goal of the project was to improve the NewGVN pass so that it can replace GVN as the main value numbering pass in LLVM.
Background
Global Value Numbering (GVN) consists of assigning value numbers such that instructions with the same value number are equivalent. NewGVN was introduced in 2016 to replace GVN. We now highlight a few aspects in which NewGVN is better than GVN.
A key advantage of NewGVN over GVN is that it is complete for loops, while GVN is only complete for acyclical code. NewGVN is complete for loops because when it first processes loops, it assumes that only the first iteration will be executed, later corroborating these assumptions—this is known as the optimistic assumption. In practice, the optimistic assumption boils down to assuming that backedges are unreachable and, consequently, that when evaluating phi instructions, the values carried by them can be ignored. For instance, in the example below, %a is optimistically evaluated to 0. This leads to evaluating %c to %x, which in turn leads to evaluating %a.i to 0. At this point, there are two possibilities: either the assumption was correct and the loop actually only executes once, and the value numbers computed so far are correct, or the instructions in the loop need to be reevaluated. Assume, for this example, that NewGVN could not prove that only one iteration is executed. Then %a once again evaluates to 0, and all other registers also evaluate to the same. Thanks to the optimistic assumption, we were able to discover that %a is loop-invariant and, moreover, that it is equal to 0.
define i32 @optimistic(i32 %x, i32 %y){
entry:
br label %loop
loop:
%a = phi i32 [0, %entry], [%a.i, %loop]
...
%c = xor i32 %x, %a
%a.i = sub i32 %x, %c
br i1 ..., label %loop,label %exit
exit:
ret i32 %a
}
On the other hand, GVN fails to detect this equivalence because it would pessimistically evaluate %a to itself, and the previously described evaluation steps would never take place.
Another advantage of NewGVN is the value numbering of memory operations using MemorySSA. It provides a functional view of memory where instructions that can modify memory produce a new memory version, which is then used by other memory operations. This greatly simplifies the detection of redundancies among memory operations. For example, two loads of the same type from equivalent pointers and memory versions are trivially equivalent.
define i32 @foo(i32 %v, ptr %p) {
entry:
; 1 = MemoryDef(liveOnEntry)
store i32 %v, ptr %p, align 4
; MemoryUse(1)
%a = load i32, ptr %p, align 4
; MemoryUse(1)
%b = load i32, ptr %p, align 4
; 2 = MemoryDef(1)
call void @f(i32 %a)
; MemoryUse(2)
%c = load i32, ptr %p, align 4
%d = sub i32 %b, %c
ret i32 %d
}
In the example above (annotated with MemorySSA), %a and %b are equivalent, while %c is not. All three loads are of the same type from the same pointer, but they don’t all load from the same memory state. Loads %a and %b load from the memory defined by the store (Memory 1), while %c loads from the memory defined by the function call (Memory 2). GVN can also detect these redundancies, but it relies on the more expensive and less general MemoryDependenceAnalysis.
Despite these and other improvements NewGVN is still not widely used, mainly because it lacks partial redundancy elimination (PRE) and because it is bug-ridden.
Implementing PRE
Our main contribution was the development of a PRE stage for NewGVN (found here). Our solution relied on generalizing Phi-of-Ops. It performs a special case of PRE where the instruction depends on a phi instruction, and an equivalent value is available on every reaching path. This is achieved in two steps: phi-translation and phi-insertion.
Phi-translation consists of evaluating the original instruction in the context of each of its block’s predecessors. Phi operands are replaced by the value incoming from the predecessor. The value is available in the predecessor if the translated instruction is equivalent to a constant, function argument, or another instruction that dominates the predecessor.
Phi-insertion occurs after phi-translation if the value is available in every predecessor. At that point, a phi of the equivalent values is constructed and used to replace the original instruction. The full process is illustrated in the following example.
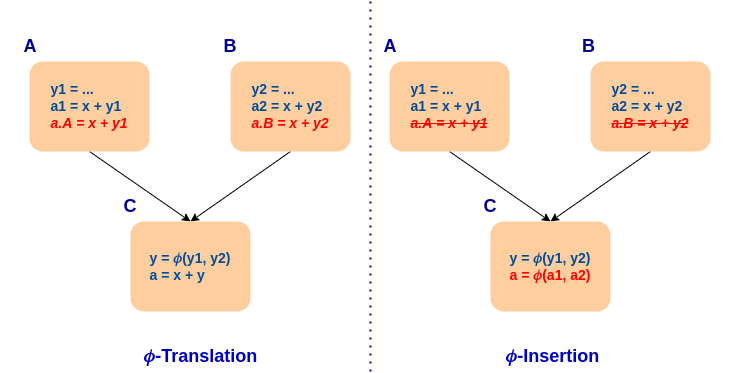
Our generalization eliminated the need for a dependent phi and introduced the ability to insert the missing values in cases where the instruction is partially redundant. To prevent increases in code size (ignoring the inserted phi instructions), the insertion is only made if it’s the only one required. The full process is illustrated in the following example.
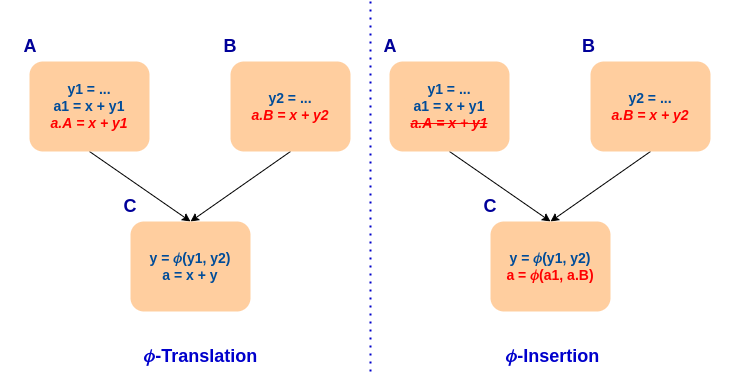
Integrating PRE into the existing framework also allowed us to gain loop-invariant code motion (LICM) for free. The optimistic assumption, combined with PRE, allows NewGVN to speculatively hoist instructions out of loops. On the other hand, LICM in GVN relies on using LoopInfo and can only handle very specific cases.
Missing Features
The two main features our PRE implementation lacks are critical edge splitting and load coercion. Critical edge splitting is required to ensure that we do not insert instructions into paths where they won’t be used. Currently, our implementation simply bails in such cases. Load coercion allows us to detect equivalences of loaded values with different types, such as loads of i32 and float, and then coerce the loaded type using conversion operations.
The difficulty in implementing these features is that NewGVN is designed to perform analysis and transformation in separate steps, while these features involve modifying the function during the analysis phase.
Results
We evaluated our implementation using the automated benchmarking tool Phoronix Test Suite from which we selected a set of 20 C/C++ applications (listed below).
| aircrack-ng | encode-flac | luajit | scimark2 |
| botan | espeak | mafft | simdjson |
| zstd | fftw | ngspice | sqlite-speedtest |
| crafty | john-the-ripper | quantlib | tjbench |
| draco | jpegxl | rnnoise | graphics-magick |
The default -O2 pipeline was used. The only change betweeen compilations was the value numbering pass used.
Despite the missing features, we observed that our implementation, on average, performs 0.4% better than GVN. However, it is important to mention that our solution hasn’t been fine-tuned to consider the rest of the optimization pipeline, which resulted in some cases where our implementation regressed compared to both GVN and the existing NewGVN. The most severe case was with jpegxl, where our implementation, on average, performed 10% worse than GVN. It’s important to note that this was an outlier; excluding jpegxl, most regressions were at most 2%. Unfortunately, due to time constraints, we were unable to study these cases in more detail.
Future Work
In the future, we plan to implement the aforementioned missing features and fine-tune the heuristics for when to perform PRE to prevent the regressions discussed in the results section. Once these issues are addressed, we’ll upstream our implementation, bringing us a step closer to reviving NewGVN.