GSoC 2025: GPU-driven I/O with io_uring
Hello everyone! My name is Rodrigo Ceccato, and for GSoC 2025 I’ve been working on GPU-driven I/O using io_uring. This 8-week project focuses on developing a prototype of a printf-like interface for the GPU, backed by Shared Virtual Memory (SVM) to directly access the io_uring submission queue.
Background
LLVM libc for GPUs implements libc functions that run natively on GPUs (e.g. math and printf routines). However, some operations rely on system calls, like printf(), which is done via a remote procedure call (RPC) to the CPU, like the image below shows.
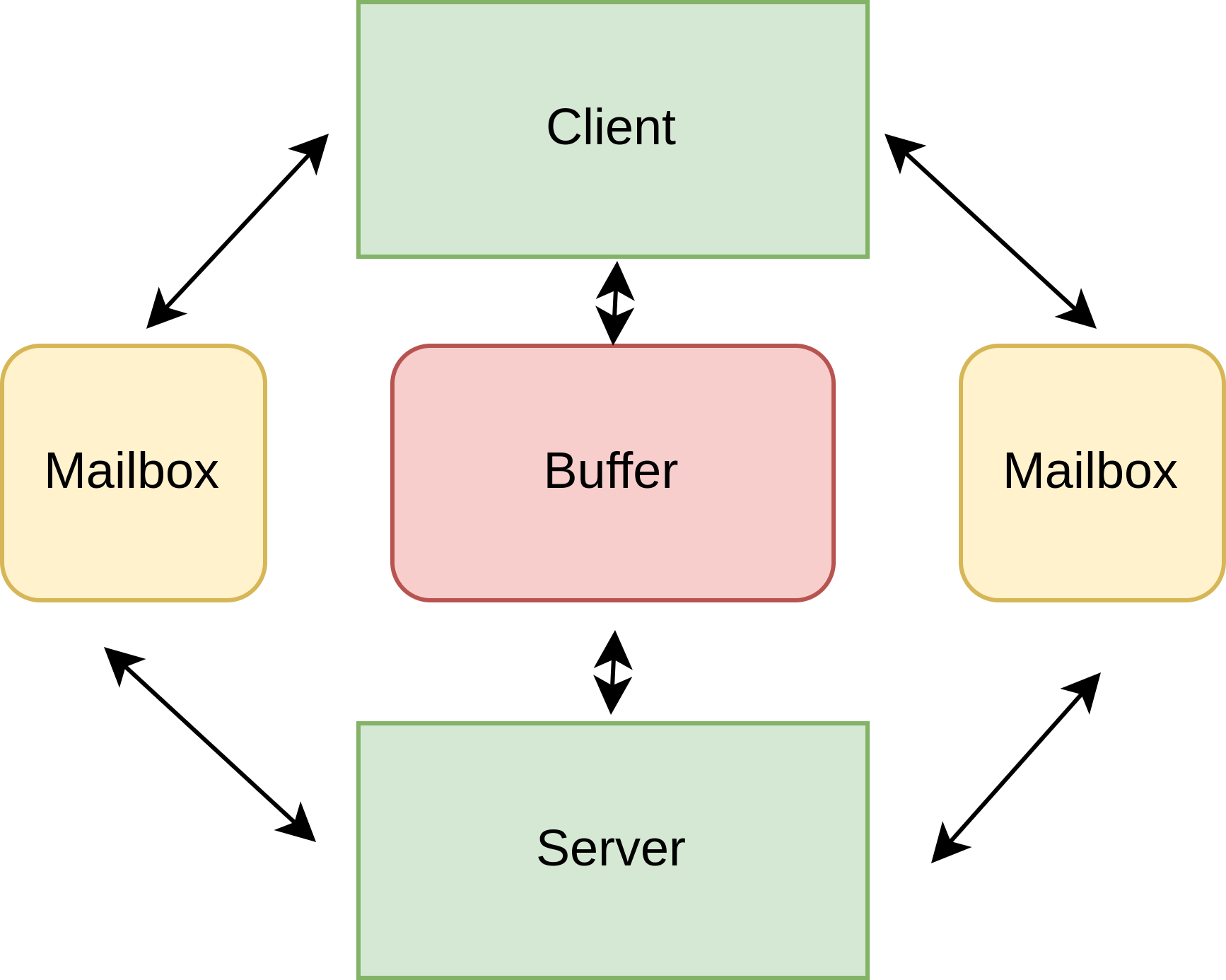
This approach uses a mailbox that is read by a user-level polling thread and transfer data through a shared buffer. This current implementation saturates at around 15MB/s, well below the PCIe bus speed.
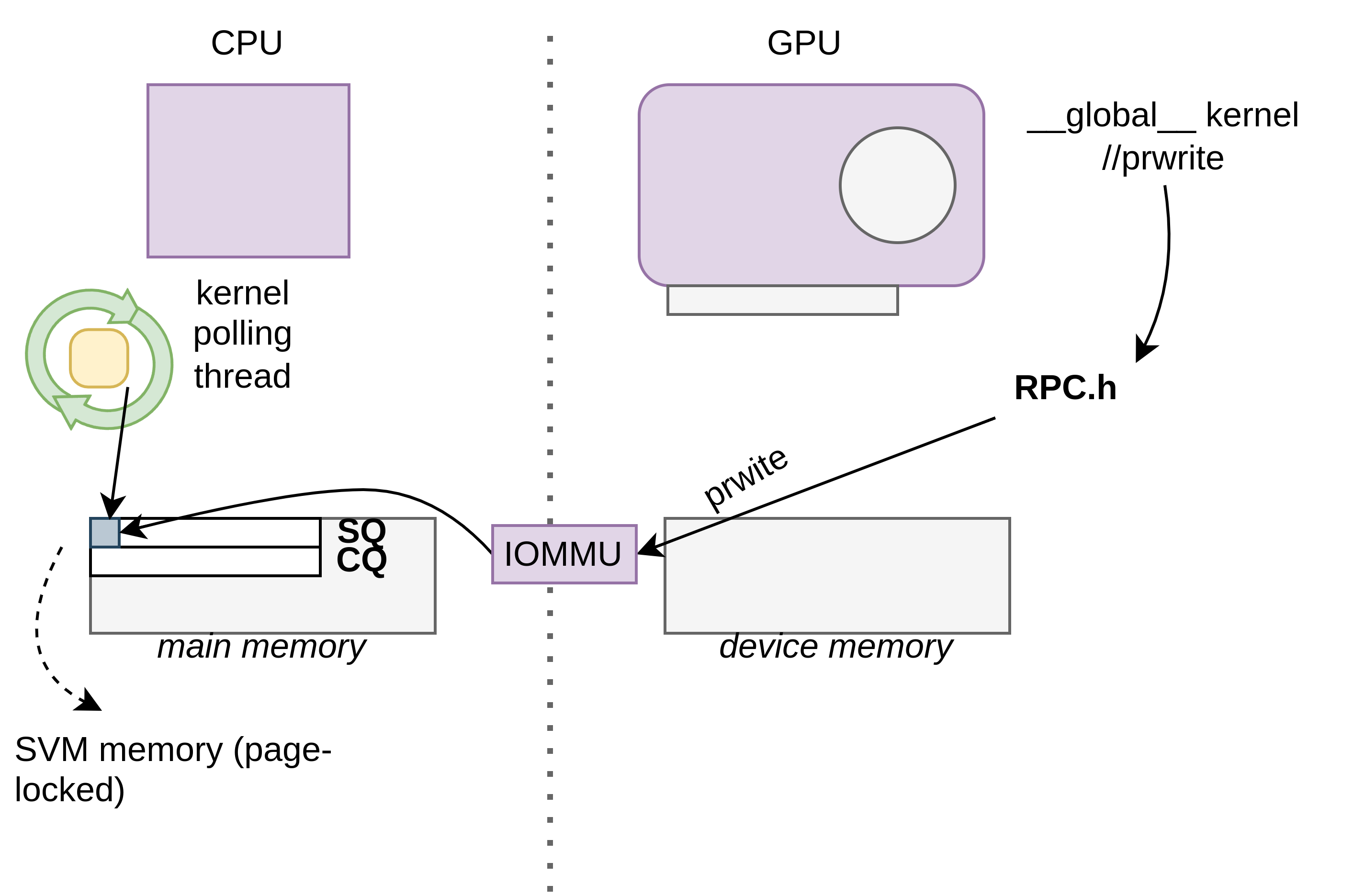
Our project explores io_uring to allow GPU-initiated I/O. io_uring is a Linux feature that lets the user register a submission queue for asynchronous and batched I/O operations. As the image below shows, we explore the concept of using a SVM region for the submission queue, and pass it to the GPU using a helper function that handles the print operation.
What We Did
We built a prototype that allows the GPU to deliver a print message using io_uring, eliminating the need to hop through a shared mailbox and a user-level polling thread. Instead, the GPU writes directly into the io_uring submission queue, which is backed by fine-grained SVM memory allocated through the HSA API. We validated the feasibility of this setup by testing whether SVM pointers could be safely passed to io_uring, and confirmed that the kernel polling thread could process submissions written entirely from GPU code. A simple print function was implemented to format messages on the device and enqueue them to the ring.
We tested the system in two modes: using synchronous io_uring flushes where the CPU manually checked completions, and using kernel-level polling where no active host thread is needed. These tests confirmed not only that the GPU could issue I/O requests directly, but also that the data remained visible and coherent across device boundaries.
We documented the entire setup process, including kernel configuration for io_uring, ROCm installation, and how to build the HSA runtime in debug mode for better diagnostics. We provided a minimal example of how to use the prototype print function inside a GPU kernel, demonstrating the full flow from device code to console output. A helper script automates compilation, kernel launch, and output collection. All source code and scripts are available in the project repository: https://github.com/phd-artifacts/gpu-libc-artifacts.
Challenges
The main challenge was figuring out if io_uring would work correctly with fine-grained SVM memory shared between the GPU and CPU. Some components in the software stack failed silently, making debugging especially difficult. For example, misconfigured io_uring setups might return success but not perform any I/O, while the HSA runtime occasionally produced only generic errors, which required a debug build of HSA. Because the system depended on multiple layers, including ROCm, HSA runtime libraries, and proper io_uring driver support, we had to take a very incremental approach, validating each component in isolation. This included writing targeted tests to verify GPU visibility, kernel polling behavior, and queue consistency across device boundaries.
Additionally, the prototype relies on fine-grained SVM, a capability currently limited to AMD platforms. Portability to other architectures such as NVIDIA will likely require fallback paths or alternate memory models, adding another axis of complexity for future work.
Future Work
Looking ahead, the next step is to integrate the prototype into LLVM’s gpu-libc, making the GPU printf functionality available as a standard library call. Beyond printing, the approach can be extended to support GPU-initiated file reads and writes, enabling more general-purpose I/O from device code. Another important direction is testing compatibility with NVIDIA GPUs and exploring fallback mechanisms for systems that lack fine-grained SVM support. Finally, further work is needed to evaluate performance bottlenecks, test in other environments and applications, including better handling of corner cases.
Acknowledgements
I would like to thank my mentors Joseph Huber and Shilei Tian for their guidance and for being consistently supportive and enthusiastic throughout the project. Their input and feedback were invaluable in navigating the technical challenges. I would also like to thank Anton Korobeynikov for offering regular office hours on GSoC guidelines and for providing helpful feedback on the midterm presentation.